Tässä artikkelissa käsittelemme DFS-algoritmia tietorakenteessa. Se on rekursiivinen algoritmi, joka etsii kaikki puun tietorakenteen tai graafin kärjet. Syvyys-ensimmäinen haku (DFS) -algoritmi alkaa graafin G alkuperäisestä solmusta ja menee syvemmälle, kunnes löydämme tavoitesolmun tai solmun, jolla ei ole lapsia.
Rekursiivisen luonteen vuoksi pinotietorakennetta voidaan käyttää DFS-algoritmin toteuttamiseen. DFS:n toteutusprosessi on samanlainen kuin BFS-algoritmi.
Vaiheittainen prosessi DFS-läpikulun toteuttamiseksi esitetään seuraavasti:
- Luo ensin pino graafin kärkien kokonaismäärällä.
- Valitse nyt mikä tahansa kärki kulkemisen aloituspisteeksi ja työnnä se pinoon.
- Työnnä sen jälkeen vierailematon kärki (pinon päällä olevan kärjen vieressä) pinon yläosaan.
- Toista nyt vaiheita 3 ja 4, kunnes pinon huipulla olevasta kärjestä ei ole jäljellä yhtään pistettä, jolle vierailla.
- Jos kärkeä ei ole jäljellä, palaa takaisin ja nosta kärki pinosta.
- Toista vaiheita 2, 3 ja 4, kunnes pino on tyhjä.
DFS-algoritmin sovellukset
DFS-algoritmin käytön sovellukset on esitetty seuraavasti -
- DFS-algoritmia voidaan käyttää topologisen lajittelun toteuttamiseen.
- Sitä voidaan käyttää kahden kärjen välisten polkujen etsimiseen.
- Sitä voidaan käyttää myös syklien havaitsemiseen kaaviossa.
- DFS-algoritmia käytetään myös yhden ratkaisun pulmiin.
- DFS:ää käytetään määrittämään, onko graafi kaksiosainen vai ei.
Algoritmi
Vaihe 1: SET STATUS = 1 (valmiustila) jokaiselle G:n solmulle
Vaihe 2: Työnnä pinon aloitussolmu A ja aseta sen STATUS = 2 (odotustila)
Vaihe 3: Toista vaiheita 4 ja 5, kunnes STACK on tyhjä
Vaihe 4: Avaa ylin solmu N. Käsittele se ja aseta sen STATUS = 3 (käsitelty tila)
Vaihe 5: Työnnä pinoon kaikki N:n naapurit, jotka ovat valmiustilassa (jonka STATUS = 1) ja aseta niiden STATUS = 2 (odotustila)
[SILMUKSEN LOPPU]
Vaihe 6: POISTU
Pseudokoodi
DFS(G,v) ( v is the vertex where the search starts ) Stack S := {}; ( start with an empty stack ) for each vertex u, set visited[u] := false; push S, v; while (S is not empty) do u := pop S; if (not visited[u]) then visited[u] := true; for each unvisited neighbour w of uu push S, w; end if end while END DFS() Esimerkki DFS-algoritmista
Ymmärretään nyt DFS-algoritmin toiminta esimerkin avulla. Alla olevassa esimerkissä on suunnattu graafi, jossa on 7 kärkeä.
ascii javassa
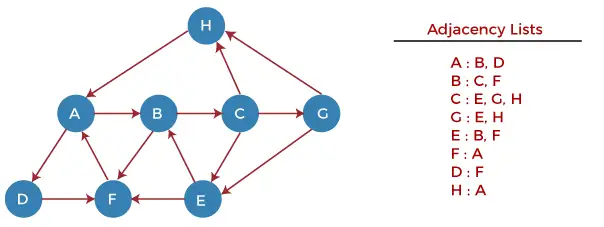
Aloitetaan nyt kaavion tutkiminen solmusta H alkaen.
Vaihe 1 - Työnnä ensin H pinoon.
STACK: H
Vaihe 2 - POP pinon ylin elementti, eli H, ja tulosta se. Nyt TYÖNTÄ kaikki H:n naapurit pinoon, jotka ovat valmiissa tilassa.
Print: H]STACK: A
Vaihe 3 - POP pinon ylin elementti, eli A, ja tulosta se. Nyt TYÖNTÄ kaikki A:n naapurit pinoon, jotka ovat valmiissa tilassa.
Print: A STACK: B, D
Vaihe 4 - POP pinon ylin elementti, eli D, ja tulosta se. Nyt TYÖNTÄ kaikki D:n naapurit pinoon, jotka ovat valmiissa tilassa.
java-menetelmän ohittaminen
Print: D STACK: B, F
Vaihe 5 - POP pinon ylin elementti, eli F, ja tulosta se. Nyt TYÖNTÄ kaikki F:n naapurit pinoon, jotka ovat valmiissa tilassa.
Print: F STACK: B
Vaihe 6 - POP pinon ylin elementti, eli B, ja tulosta se. Nyt TYÖNTÄ kaikki B:n naapurit pinoon, jotka ovat valmiissa tilassa.
Print: B STACK: C
Vaihe 7 - POP pinon ylin elementti, eli C, ja tulosta se. Nyt TYÖNTÄ kaikki C:n naapurit pinoon, jotka ovat valmiissa tilassa.
Print: C STACK: E, G
Vaihe 8 - POP pinon ylin elementti eli G ja TYÖNTÄ kaikki G:n naapurit pinoon, jotka ovat valmiina.
Print: G STACK: E
Vaihe 9 - POP pinon ylin elementti eli E ja TYÖNTÄ kaikki E:n naapurit pinoon, jotka ovat valmiina.
Print: E STACK:
Nyt kaikki graafin solmut on ajettu läpi ja pino on tyhjä.
Syvyys-ensin hakualgoritmin monimutkaisuus
DFS-algoritmin aikamonimutkaisuus on O(V+E) , jossa V on graafin kärkien lukumäärä ja E on graafin reunojen lukumäärä.
DFS-algoritmin tilamonimutkaisuus on O(V).
DFS-algoritmin toteutus
Katsotaanpa nyt DFS-algoritmin toteutusta Javassa.
Tässä esimerkissä kaavio, jota käytämme koodin osoittamiseen, on annettu seuraavasti -

/*A sample java program to implement the DFS algorithm*/ import java.util.*; class DFSTraversal { private LinkedList adj[]; /*adjacency list representation*/ private boolean visited[]; /* Creation of the graph */ DFSTraversal(int V) /*'V' is the number of vertices in the graph*/ { adj = new LinkedList[V]; visited = new boolean[V]; for (int i = 0; i <v; i++) adj[i]="new" linkedlist(); } * adding an edge to the graph void insertedge(int src, int dest) { adj[src].add(dest); dfs(int vertex) visited[vertex]="true;" *mark current node as visited* system.out.print(vertex + ' '); iterator it="adj[vertex].listIterator();" while (it.hasnext()) n="it.next();" if (!visited[n]) dfs(n); public static main(string args[]) dfstraversal dfstraversal(8); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, system.out.println('depth first traversal for is:'); graph.dfs(0); < pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/28/dfs-algorithm-3.webp" alt="DFS algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the depth-first search technique, its example, complexity, and implementation in the java programming language. Along with that, we have also seen the applications of the depth-first search algorithm.</p> <p>So, that's all about the article. Hope it will be helpful and informative to you.</p> <hr></v;>