BERT, lyhenne Transformersin kaksisuuntaisten kooderien esityksiin , on avoin lähdekoodi koneoppimiskehys suunniteltu valtakuntaa varten luonnollisen kielen käsittely (NLP) . Tämä vuonna 2018 syntyneen kehyksen suunnittelivat Google AI Languagen tutkijat. Artikkelin tarkoituksena on tutkia BERTin arkkitehtuuri, toiminta ja sovellukset .
Mikä on BERT?
BERT (Bidirectional Encoder Representations from Transformers) hyödyntää muuntajapohjaista hermoverkkoa ymmärtääkseen ja luodakseen ihmisen kaltaista kieltä. BERT käyttää vain enkooderin arkkitehtuuria. Alkuperäisessä Muuntaja-arkkitehtuuri , on sekä enkooderi- että dekooderimoduuleja. Päätös käyttää BERT:ssä vain kooderia sisältävää arkkitehtuuria viittaa siihen, että ensisijaisesti painotetaan tulosekvenssien ymmärtämistä lähtösekvenssien luomisen sijaan.
BERTin kaksisuuntainen lähestymistapa
Perinteiset kielimallit käsittelevät tekstiä peräkkäin, joko vasemmalta oikealle tai oikealta vasemmalle. Tämä menetelmä rajoittaa mallin tietoisuuden kohdesanaa edeltävään välittömään kontekstiin. BERT käyttää kaksisuuntaista lähestymistapaa, jossa otetaan huomioon sekä sanan vasen että oikea konteksti lauseessa. Sen sijaan, että analysoidaan tekstiä peräkkäin, BERT tarkastelee kaikkia lauseen sanoja samanaikaisesti.
Esimerkki: Pankki sijaitsee joen _______.
Yksisuuntaisessa mallissa aihion ymmärtäminen riippuisi suuresti edeltävistä sanoista, ja mallilla saattaa olla vaikeuksia erottaa, viittaako pankki rahoituslaitokseen vai joen puoleen.
Kaksisuuntaisena BERT ottaa huomioon samanaikaisesti sekä vasemman (ranta sijaitsee) että oikean (joen) kontekstin, mikä mahdollistaa vivahteikkaamman ymmärryksen. Se ymmärtää, että puuttuva sana liittyy todennäköisesti pankin maantieteelliseen sijaintiin, mikä osoittaa kaksisuuntaisen lähestymistavan tuoman kontekstuaalisen rikkauden.
Esiharjoittelu ja hienosäätö
BERT-malli käy läpi kaksivaiheisen prosessin:
- Esikoulutus: Suuri määrä nimeämätöntä tekstiä oppiaksesi kontekstuaaliset upotukset.
- Merkittyjen tietojen hienosäätö NLP tehtäviä.
Suurten tietojen esikoulutus
- BERT on esikoulutettu suureen määrään merkitsemätöntä tekstidataa. Malli oppii kontekstuaaliset upotukset, jotka ovat sanojen esityksiä, jotka ottavat huomioon niiden ympäröivän kontekstin lauseessa.
- BERT harjoittaa erilaisia ohjaamattomia esikoulutustehtäviä. Se voi esimerkiksi oppia ennustamaan lauseesta puuttuvia sanoja (naamiokielimalli tai MLM-tehtävä), ymmärtämään kahden lauseen välistä suhdetta tai ennustamaan parin seuraavan lauseen.
Merkittyjen tietojen hienosäätö
- Esiopetusvaiheen jälkeen BERT-malli, joka on varustettu kontekstuaalisilla upotuksilla, hienosäädetään tiettyjä luonnollisen kielen käsittelyn (NLP) tehtäviä varten. Tämä vaihe räätälöi mallin kohdistetumpiin sovelluksiin mukauttamalla sen yleistä kielitajua tietyn tehtävän vivahteisiin.
- BERT on hienosäädetty käyttämällä merkittyjä tietoja, jotka liittyvät kiinnostaviin loppupään tehtäviin. Näihin tehtäviin voi kuulua tunteiden analysointi, kysymyksiin vastaaminen, nimetyn entiteetin tunnistus tai mikä tahansa muu NLP-sovellus. Mallin parametrit on säädetty optimoimaan sen suorituskyky kulloisenkin tehtävän erityisvaatimuksia vastaavaksi.
BERTin yhtenäinen arkkitehtuuri mahdollistaa sen sopeutumisen erilaisiin loppupään tehtäviin pienin muutoksin, mikä tekee siitä monipuolisen ja erittäin tehokkaan työkalun luonnollisen kielen ymmärtäminen ja käsittelyyn.
Miten BERT toimii?
BERT on suunniteltu luomaan kielimalli, joten vain enkooderimekanismia käytetään. Tokenien sarja syötetään Transformer-enkooderille. Nämä tunnukset upotetaan ensin vektoreihin ja käsitellään sitten hermoverkossa. Tulos on vektoreiden sarja, joista jokainen vastaa syöttötunnusta ja tarjoaa kontekstuaalisia esityksiä.
Kielimalleja opetettaessa ennustetavoitteen määrittäminen on haaste. Monet mallit ennustavat sekvenssin seuraavan sanan, mikä on suuntaava lähestymistapa ja saattaa rajoittaa kontekstin oppimista. BERT vastaa tähän haasteeseen kahdella innovatiivisella koulutusstrategialla:
- Masked Language Model (MLM)
- Seuraavan lauseen ennustus (NSP)
1. Masked Language Model (MLM)
BERT:n esikoulutusprosessissa osa kunkin syöttösekvenssin sanoista peitetään ja mallia opetetaan ennustamaan näiden maskattujen sanojen alkuperäiset arvot ympäröivien sanojen tarjoaman kontekstin perusteella.
Yksinkertaisin termein,
- Peittävät sanat: Ennen kuin BERT oppii lauseista, se piilottaa joitain sanoja (noin 15 %) ja korvaa ne erityisellä symbolilla, kuten [MASK].
- Piilotettujen sanojen arvailu: BERTin tehtävänä on selvittää, mitä nämä piilotetut sanat ovat, katsomalla niiden ympärillä olevia sanoja. Se on kuin arvauspeliä, jossa jotkut sanat puuttuvat, ja BERT yrittää täyttää kohdat.
- Miten BERT oppii:
- BERT lisää erityisen kerroksen oppimisjärjestelmänsä päälle näiden arvausten tekemiseksi. Sitten se tarkistaa, kuinka lähellä sen arvaukset ovat todellisia piilotettuja sanoja.
- Se tekee tämän muuntamalla arvauksensa todennäköisyyksiksi sanoen: Luulen, että tämä sana on X, ja olen siitä niin varma.
- Erityistä huomiota piilotettuihin sanoihin
- BERT:n pääpaino koulutuksen aikana on saada nämä piilotetut sanat oikein. Se välittää vähemmän sanojen ennustamisesta, joita ei ole piilotettu.
- Tämä johtuu siitä, että todellinen haaste on puuttuvien osien selvittäminen, ja tämä strategia auttaa BERT:tä ymmärtämään sanojen merkityksen ja kontekstin todella hyvin.
Teknisesti sanottuna
- BERT lisää luokituskerroksen kooderin lähdön päälle. Tämä kerros on ratkaisevan tärkeä naamioitujen sanojen ennustamisessa.
- Luokittelukerroksen lähtövektorit kerrotaan upotusmatriisilla, jolloin ne muunnetaan sanastoulottuvuudeksi. Tämä vaihe auttaa kohdistamaan ennustetut esitykset sanastotilan kanssa.
- Sanaston jokaisen sanan todennäköisyys lasketaan käyttämällä SoftMax-aktivointitoiminto . Tämä vaihe luo todennäköisyysjakauman koko sanastolle kullekin peitetylle sijainnille.
- Harjoittelun aikana käytetty häviöfunktio ottaa huomioon vain maskattujen arvojen ennusteen. Mallia rangaistaan sen ennusteiden ja maskattujen sanojen todellisten arvojen välisestä poikkeamasta.
- Malli konvergoi hitaammin kuin suuntamallit. Tämä johtuu siitä, että koulutuksen aikana BERT huolehtii vain peitettyjen arvojen ennustamisesta jättäen huomioimatta peittämättömien sanojen ennustuksen. Tällä strategialla saavutettu lisääntynyt kontekstitietoisuus kompensoi hitaampaa lähentymistä.
2. Seuraavan lauseen ennustus (NSP)
BERT ennustaa, liittyykö toinen lause ensimmäiseen. Tämä tehdään muuntamalla [CLS]-tunnisteen tulos 2 × 1 -muotoiseksi vektoriksi käyttämällä luokituskerrosta ja laskemalla sitten todennäköisyys sille, seuraako toinen lause ensimmäistä käyttämällä SoftMaxia.
- Koulutusprosessissa BERT oppii ymmärtämään lauseparien välistä suhdetta ennustaen, seuraako toinen lause alkuperäisen asiakirjan ensimmäistä.
- 50 %:lla syötepareista toinen virke on alkuperäisen dokumentin seuraavana virkkeenä ja lopuilla 50 %:lla on satunnaisesti valittu lause.
- Auttaa mallia erottamaan toisiinsa liittyvät ja irrotetut lauseparit. Syöte käsitellään ennen mallin syöttämistä:
- [CLS]-tunnus lisätään ensimmäisen virkkeen alkuun ja [SEP]-tunnus lisätään jokaisen virkkeen loppuun.
- Jokaiseen merkkiin lisätään lauseen upotus, joka ilmaisee lauseen A tai lauseen B.
- Paikallinen upotus osoittaa kunkin merkin sijainnin sarjassa.
- BERT ennustaa, liittyykö toinen lause ensimmäiseen. Tämä tehdään muuntamalla [CLS]-tunnisteen tulos 2 × 1 -muotoiseksi vektoriksi käyttämällä luokituskerrosta ja laskemalla sitten todennäköisyys sille, seuraako toinen lause ensimmäistä käyttämällä SoftMaxia.
BERT-mallin harjoittelun aikana harjoitellaan yhdessä Masked LM:ää ja Next Sentence Predictionia. Mallin tavoitteena on minimoida Masked LM:n ja Next Sentence Predictionin yhdistetty häviöfunktio, mikä johtaa vankkaan kielimalliin, jolla on parannettu kyky ymmärtää lauseiden kontekstia ja lauseiden välisiä suhteita.
Miksi harjoittaa Masked LM:ää ja Next Sentence Predictionia yhdessä?
Masked LM auttaa BERTiä ymmärtämään lauseen kontekstin ja Seuraavan lauseen ennustus auttaa BERTiä ymmärtämään lauseparien välisen yhteyden tai suhteen. Näin ollen molempien strategioiden yhdessä harjoitteleminen varmistaa, että BERT oppii laajan ja kattavan kielen ymmärtämisen ja vangitsee sekä lauseiden yksityiskohdat että lauseiden välisen virran.
BERT-arkkitehtuurit
BERT:n arkkitehtuuri on monikerroksinen kaksisuuntainen muuntajakooderi, joka on melko samanlainen kuin muuntajamalli. Muuntaja-arkkitehtuuri on kooderi-dekooderiverkko, joka käyttää itsetunto kooderin puolella ja huomiota dekooderin puolella.
- BERTBASEon 1 2 kerrosta Encoder-pinossa kun taas BERTSUURIon 24 kerrosta Encoder-pinossa . Nämä ovat enemmän kuin alkuperäisessä asiakirjassa kuvattu Transformer-arkkitehtuuri ( 6 enkooderikerrosta ).
- BERT-arkkitehtuureissa (BASE ja LARGE) on myös suurempia myötäkytkentäverkkoja (vastaavasti 768 ja 1024 piilotettua yksikköä) ja enemmän huomiopäitä (12 ja 16 vastaavasti) kuin alkuperäisessä asiakirjassa ehdotettu Transformer-arkkitehtuuri. Se sisältää 512 piilotettua yksikköä ja 8 huomiopäätä .
- BERTBASEsisältää 110 miljoonaa parametria, kun taas BERTSUURIon 340M parametreja.

BERT BASE ja BERT LARGE arkkitehtuuri.
Tämä malli ottaa CLS token syötteenä ensin, sitten sitä seuraa sanasarja syötteenä. Tässä CLS on luokitustunnus. Sitten se välittää syötteen yllä oleville kerroksille. Jokainen kerros koskee itsetunto ja välittää tuloksen eteenpäinkytkentäverkon kautta, minkä jälkeen se luovuttaa sen seuraavalle kooderille. Malli tulostaa piilokokoisen vektorin ( 768 BERT BASE:lle). Jos haluamme tulostaa luokittimen tästä mallista, voimme ottaa CLS-merkkiä vastaavan lähdön.
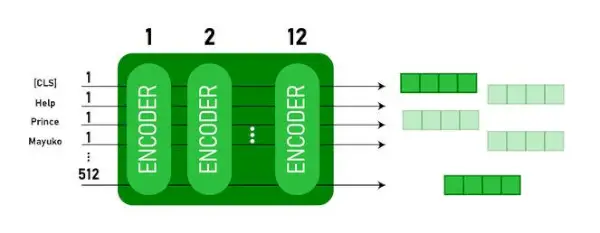
BERT-tulostus upotuksina
Nyt tätä koulutettua vektoria voidaan käyttää useiden tehtävien suorittamiseen, kuten luokitteluun, kääntämiseen jne. Esimerkiksi paperilla saavutetaan hienoja tuloksia vain käyttämällä yhtä kerrosta Neuraaliverkko BERT-mallilla luokitustehtävässä.
Kuinka käyttää BERT-mallia NLP:ssä?
BERTiä voidaan käyttää erilaisiin luonnollisen kielen prosessointitehtäviin (NLP), kuten:
1. Luokittelutehtävä
- BERT:tä voidaan käyttää esimerkiksi luokittelutehtäviin tunneanalyysi , tavoitteena on luokitella teksti eri luokkiin (positiivinen/negatiivinen/neutraali), BERT:tä voidaan käyttää lisäämällä luokituskerros Transformer-ulostulon yläosaan [CLS]-tunnisteelle.
- [CLS]-tunnus edustaa koottua tietoa koko syöttösekvenssistä. Tätä yhdistettyä esitystä voidaan sitten käyttää syötteenä luokitustasolle, jotta voidaan tehdä ennusteita tietylle tehtävälle.
2. Kysymykseen vastaaminen
- Kysymysvastaustehtävissä, joissa mallia vaaditaan paikantamaan ja merkitsemään vastaus tietyssä tekstisekvenssissä, BERT voidaan kouluttaa tähän tarkoitukseen.
- BERT on koulutettu vastaamaan kysymyksiin oppimalla kaksi lisävektoria, jotka merkitsevät vastauksen alkua ja loppua. Harjoittelun aikana mallille tarjotaan kysymyksiä ja niitä vastaavia kohtia, ja se oppii ennustamaan vastauksen alku- ja loppukohdan kohdan sisällä.
3. Nimetty entiteettitunnistus (NER)
- BERT:tä voidaan käyttää NER:lle, jossa tavoitteena on tunnistaa ja luokitella entiteetit (esim. henkilö, organisaatio, päivämäärä) tekstisekvenssissä.
- BERT-pohjaista NER-mallia opetetaan ottamalla kunkin muuntajan lähtövektori ja syöttämällä se luokituskerrokseen. Taso ennustaa nimetyn entiteettitunnisteen kullekin tunnukselle, mikä osoittaa entiteetin tyypin, jota se edustaa.
Kuinka tokenoida ja koodata tekstiä BERT:n avulla?
Tekstin tokenointiin ja koodaukseen BERT:n avulla käytämme Pythonin muuntajakirjastoa.
Muuntajien asennuskomento:
!pip install transformers>
- Lataamme valmiiksi koulutetun BERT-tunnuksen koteloidulla sanastolla käyttämällä BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(teksti) tokenisoi syötetyn tekstin ja muuntaa sen merkkitunnusten sarjaksi.
- tulosta (Token ID:t:, koodaus) tulostaa koodauksen jälkeen saadut tunnukset.
- tokenizer.convert_ids_to_tokens(encoding) muuntaa tunnukset takaisin vastaaviksi tunnuksiksi.
- tulosta (Tokens:, tokens) tulostaa tunnukset, jotka on saatu token-tunnusten muuntamisen jälkeen
Python 3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Lähtö:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> The tokenizer.encode menetelmä lisää erityistä [CLS] – luokitus ja [SEP] – erotin merkit koodatun sekvenssin alussa ja lopussa.
BERT:n sovellus
BERTiä käytetään:
- Tekstin esitys: BERT:tä käytetään luomaan sanan upotuksia tai esityksiä lauseessa oleville sanoille.
- Nimetyn kokonaisuuden tunnistus (NER) : BERT voidaan hienosäätää nimettyjen entiteettien tunnistustehtäviin, joissa tavoitteena on tunnistaa entiteetit, kuten ihmisten, organisaatioiden, paikkojen jne. nimet tietyssä tekstissä.
- Tekstin luokittelu: BERT:tä käytetään laajasti tekstin luokittelutehtäviin, mukaan lukien mielialan analysointi, roskapostin havaitseminen ja aiheiden luokittelu. Se on osoittanut erinomaisen suorituskyvyn tekstidatan kontekstin ymmärtämisessä ja luokittelussa.
- Kysymysvastausjärjestelmät: BERT:tä on sovellettu kysymysvastausjärjestelmiin, joissa mallia koulutetaan ymmärtämään kysymyksen konteksti ja antamaan asiaankuuluvia vastauksia. Tämä on erityisen hyödyllistä tehtävissä, kuten luetun ymmärtämisessä.
- Konekäännös: BERTin kontekstuaalisia upotuksia voidaan hyödyntää konekäännösjärjestelmien parantamisessa. Malli vangitsee kielen vivahteet, jotka ovat ratkaisevan tärkeitä tarkan kääntämisen kannalta.
- Tekstin yhteenveto: BERT:tä voidaan käyttää abstraktissa tekstin yhteenvedossa, jossa malli tuottaa tiiviitä ja merkityksellisiä tiivistelmiä pitkistä teksteistä ymmärtämällä kontekstin ja semantiikan.
- Keskusteleva tekoäly: BERT:tä käytetään rakentamaan keskustelullisia tekoälyjärjestelmiä, kuten chatbotteja, virtuaalisia avustajia ja dialogijärjestelmiä. Sen kyky tarttua kontekstiin tekee siitä tehokkaan luonnollisen kielen vastausten ymmärtämisessä ja luomisessa.
- Semanttinen samankaltaisuus: BERT-upotusten avulla voidaan mitata lauseiden tai asiakirjojen semanttista samankaltaisuutta. Tämä on arvokasta tehtävissä, kuten kaksoiskappaleiden havaitsemisessa, parafraasien tunnistamisessa ja tiedonhaussa.
BERT vs GPT
Erot BERT:n ja GPT:n välillä ovat seuraavat:
| BERT | GPT | |
|---|---|---|
| Arkkitehtuuri | BERT on suunniteltu kaksisuuntaiseen esityksen oppimiseen. Se käyttää peitetyn kielimallin tavoitetta, jossa se ennustaa puuttuvat sanat lauseesta sekä vasemman että oikean kontekstin perusteella. | GPT puolestaan on suunniteltu generatiiviseen kielen mallintamiseen. Se ennustaa lauseen seuraavan sanan edellisessä kontekstissa käyttämällä yksisuuntaista autoregressiivistä lähestymistapaa. |
| Esikoulutuksen tavoitteet | BERT on esikoulutettu käyttämällä maskattua kielimallin tavoitetta ja seuraavan lauseen ennustamista. Se keskittyy kaksisuuntaisen kontekstin vangitsemiseen ja lauseen sanojen välisten suhteiden ymmärtämiseen. | GPT on valmiiksi koulutettu ennustamaan lauseen seuraava sana, mikä rohkaisee mallia oppimaan yhtenäisen kielen esityksen ja luomaan kontekstuaalisesti relevantteja sekvenssejä. |
| Kontekstin ymmärtäminen | BERT on tehokas tehtäviin, jotka vaativat syvällistä ymmärrystä lauseen kontekstista ja suhteista, kuten tekstin luokittelu, nimettyjen entiteettien tunnistus ja kysymyksiin vastaaminen. | GPT on vahva luomaan yhtenäistä ja asiayhteyteen liittyvää tekstiä. Sitä käytetään usein luovissa tehtävissä, dialogijärjestelmissä ja tehtävissä, jotka edellyttävät luonnollisen kielen sekvenssien luomista. |
| Tehtävätyypit ja käyttötapaukset
| Käytetään yleisesti tehtävissä, kuten tekstin luokittelu, nimettyjen entiteettien tunnistus, tunneanalyysi ja kysymyksiin vastaaminen. | Sovelletaan tehtävissä, kuten tekstin luominen, dialogijärjestelmät, yhteenveto ja luova kirjoittaminen. |
| Hienosäätö vs Few-Shot Learning | BERT on usein hienosäädetty tiettyihin loppupään tehtäviin merkityillä tiedoilla mukauttaakseen esikoulutetut esitykset käsillä olevaan tehtävään. | GPT on suunniteltu suorittamaan muutaman kerran oppimista, jossa se voi yleistää uusiin tehtäviin minimaalisella tehtäväkohtaisella harjoitusdatalla. |
Tarkista myös:
- Tunneluokiteltu BERT:n avulla
- Kuinka luoda Wordin upottaminen BERT:n avulla?
- BART-malli tekstin automaattiseen täydennykseen NLP:ssä
- Myrkyllisten kommenttien luokittelu BERT:n avulla
- Seuraavan lauseen ennustaminen BERT:n avulla
Usein kysytyt kysymykset (FAQ)
K. Mihin BERTiä käytetään?
BERTiä käytetään NLP-tehtävien suorittamiseen, kuten tekstin esittämiseen, nimettyjen entiteettien tunnistus, tekstin luokittelu, Q&A-järjestelmät, konekäännös, tekstin yhteenveto ja paljon muuta.
K. Mitkä ovat BERT-mallin edut?
BERT-kielimalli erottuu joukosta sen laajan esikoulutuksen ansiosta useilla kielillä ja tarjoaa laajan kielellisen kattavuuden muihin malleihin verrattuna. Tämä tekee BERT:stä erityisen edullisen muissa kuin englanninkielisissä projekteissa, koska se tarjoaa vankat kontekstuaaliset esitykset ja semanttisen ymmärryksen useilla eri kielillä, mikä lisää sen monipuolisuutta monikielisissä sovelluksissa.
K. Miten BERT toimii tunneanalyysissä?
BERT on erinomaista tunteiden analysoinnissa hyödyntämällä kaksisuuntaisen esitystavan oppimista vangitakseen kontekstuaalisia vivahteita, semanttisia merkityksiä ja syntaktisia rakenteita tietyssä tekstissä. Tämä antaa BERT:lle mahdollisuuden ymmärtää lauseessa ilmaistuja tunteita ottamalla huomioon sanojen väliset suhteet, mikä johtaa erittäin tehokkaisiin mielipideanalyysin tuloksiin.
hakemiston uudelleennimeäminen linuxissa
K. Perustuuko Google BERTiin?
BERT ja RankBrain ovat Googlen hakualgoritmin osia kyselyjen ja verkkosivujen sisällön käsittelemiseksi saadakseen paremman käsityksen hakutulosten parantamiseksi.