Seuraava arkkitehtuuri selittää kyselyn lähettämisen Hiveen.
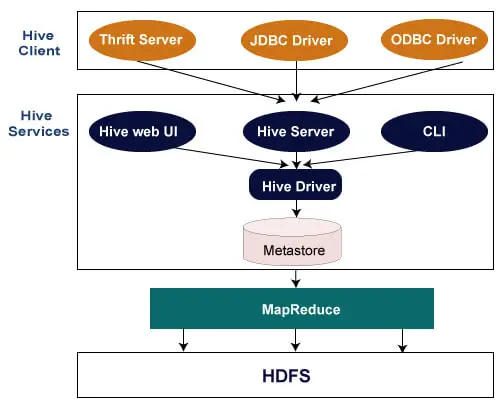
Hive asiakas
Hive mahdollistaa sovellusten kirjoittamisen eri kielillä, mukaan lukien Java, Python ja C++. Se tukee erilaisia asiakkaita, kuten: -
- Thrift Server - Se on monikielinen palveluntarjoajaalusta, joka palvelee pyyntöjä kaikilta niiltä ohjelmointikieliltä, jotka tukevat Thriftiä.
- JDBC-ohjain - Sitä käytetään yhteyden muodostamiseen hiven ja Java-sovellusten välille. JDBC-ohjain on luokassa org.apache.hadoop.hive.jdbc.HiveDriver.
- ODBC-ohjain – Sen avulla ODBC-protokollaa tukevat sovellukset voivat muodostaa yhteyden Hiveen.
Hive-palvelut
Hiven tarjoamat palvelut ovat seuraavat:
- Hive CLI - Hive CLI (Command Line Interface) on kuori, jossa voimme suorittaa Hiven kyselyjä ja komentoja.
- Hive Web -käyttöliittymä - Hive Web -käyttöliittymä on vain vaihtoehto Hiven CLI:lle. Se tarjoaa verkkopohjaisen graafisen käyttöliittymän Hive-kyselyjen ja -komentojen suorittamiseen.
- Hive MetaStore - Se on keskusvarasto, joka tallentaa kaikki varaston eri taulukoiden ja osioiden rakennetiedot. Se sisältää myös sarakkeen metatiedot ja sen tyyppitiedot, serialisoijat ja deserialisoijat, joita käytetään tietojen lukemiseen ja kirjoittamiseen, sekä vastaavat HDFS-tiedostot, joihin tiedot on tallennettu.
- Hive Server - Sitä kutsutaan Apache Thrift Serveriksi. Se hyväksyy eri asiakkaiden pyynnöt ja toimittaa sen Hive Driverille.
- Hive Driver - Se vastaanottaa kyselyitä eri lähteistä, kuten verkkokäyttöliittymästä, CLI:stä, Thriftistä ja JDBC/ODBC-ohjaimesta. Se siirtää kyselyt kääntäjälle.
- Hive Compiler - Kääntäjän tarkoitus on jäsentää kysely ja suorittaa semanttinen analyysi eri kyselylohkoille ja lausekkeille. Se muuntaa HiveQL-lauseet MapReduce-töiksi.
- Hive Execution Engine - Optimizer luo loogisen suunnitelman DAG-muodossa kartta-reduce-tehtävistä ja HDFS-tehtävistä. Lopulta suoritusmoottori suorittaa saapuvat tehtävät niiden riippuvuuksien järjestyksessä.