A Konvoluutiohermoverkko (CNN) on eräänlainen Deep Learning -hermoverkkoarkkitehtuuri, jota käytetään yleisesti Computer Visionissa. Tietokonenäkö on tekoälyn kenttä, jonka avulla tietokone voi ymmärtää ja tulkita kuvaa tai visuaalista dataa.
Mitä tulee koneoppimiseen, Keinotekoiset hermoverkot suoriutua todella hyvin. Neuraaliverkkoja käytetään erilaisissa tietojoukoissa, kuten kuvissa, äänessä ja tekstissä. Erityyppisiä hermoverkkoja käytetään eri tarkoituksiin, esimerkiksi käyttämiemme sanojen sekvenssin ennustamiseen Toistuvat hermoverkot tarkemmin an LSTM , samoin kuvan luokittelussa käytämme Convolution Neural -verkkoja. Tässä blogissa aiomme rakentaa perusrakennuspalikka CNN:lle.
Tavallisessa hermoverkossa on kolmen tyyppisiä kerroksia:
- Syöttötasot: Se on kerros, jossa annamme syötteen mallillemme. Tämän kerroksen neuronien määrä on yhtä suuri kuin datamme ominaisuuksien kokonaismäärä (pikseleiden määrä kuvan tapauksessa).
- Piilotettu kerros: Tulokerroksen syöttö syötetään sitten piilotettuun kerrokseen. Piilotettuja tasoja voi olla useita mallistamme ja tietokoosta riippuen. Jokaisessa piilokerroksessa voi olla eri määrä neuroneja, jotka ovat yleensä suurempia kuin piirteiden lukumäärä. Kunkin kerroksen tulos lasketaan matriisikertomalla edellisen kerroksen tuotos kyseisen kerroksen opittavilla painoilla ja lisäämällä sitten opittavia harhoja, joita seuraa aktivointitoiminto, joka tekee verkosta epälineaarisen.
- Tulostuskerros: Piilotetun kerroksen tulos syötetään sitten logistiseen funktioon, kuten sigmoid tai softmax, joka muuntaa kunkin luokan lähdön kunkin luokan todennäköisyyspisteiksi.
Tiedot syötetään malliin ja tulos jokaisesta kerroksesta saadaan yllä olevasta vaiheesta eteenpäin , laskemme sitten virheen käyttämällä virhefunktiota, joitain yleisiä virhefunktioita ovat ristientropia, neliöhäviövirhe jne. Virhefunktio mittaa, kuinka hyvin verkko toimii. Sen jälkeen etenemme takaisin malliin laskemalla derivaatat. Tätä vaihetta kutsutaan Convolutional Neural Network (CNN) on laajennettu versio keinotekoiset neuroverkot (ANN) jota käytetään pääasiassa ominaisuuden poimimiseen ruudukkomaisesta matriisitietojoukosta. Esimerkiksi visuaaliset tietojoukot, kuten kuvat tai videot, joissa datakuvioilla on laaja rooli.
CNN-arkkitehtuuri
Konvoluutiohermoverkko koostuu useista kerroksista, kuten syöttökerroksesta, konvoluutiokerroksesta, poolauskerroksesta ja täysin yhdistetyistä kerroksista.

Yksinkertainen CNN-arkkitehtuuri
Konvoluutiotaso käyttää suodattimia syöttökuvaan ominaisuuksien poimimiseksi, Pooling-kerros laskee kuvan näytteitä laskennan vähentämiseksi, ja täysin yhdistetty kerros tekee lopullisen ennusteen. Verkko oppii optimaaliset suodattimet takaisin leviämisen ja gradientin laskeutumisen kautta.
Kuinka Convolutional Layers toimii
Convolution Neural Networks tai covnetit ovat hermoverkkoja, jotka jakavat parametrinsa. Kuvittele, että sinulla on kuva. Se voidaan esittää kuutiona, jolla on pituus, leveys (kuvan mitat) ja korkeus (eli kanava, koska kuvissa on yleensä punainen, vihreä ja sininen kanava).
Kuvittele nyt, että otat pienen palan tästä kuvasta ja käytät siinä pientä hermoverkkoa, jota kutsutaan suodattimeksi tai ytimeksi, ja jossa on esimerkiksi K-lähtö ja edustaa niitä pystysuunnassa. Liu'uta nyt tätä hermoverkkoa koko kuvan poikki, minkä seurauksena saamme toisen kuvan, jolla on eri leveydet, korkeudet ja syvyydet. Vain R-, G- ja B-kanavien sijaan meillä on nyt enemmän kanavia, mutta pienempi leveys ja korkeus. Tätä operaatiota kutsutaan Convolution . Jos korjaustiedoston koko on sama kuin kuvan koko, se on tavallinen hermoverkko. Tämän pienen paikan ansiosta meillä on vähemmän painoja.
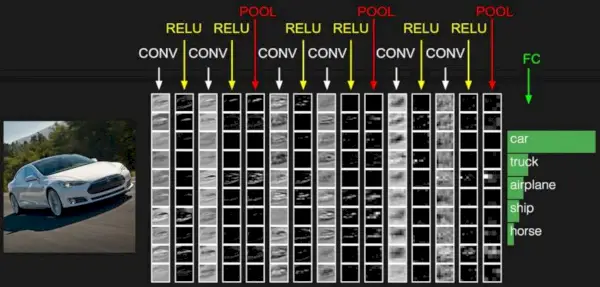
Kuvan lähde: Deep Learning Udacity
Puhutaanpa nyt vähän matematiikasta, joka on mukana koko konvoluutioprosessissa.
arraylist java
- Konvoluutiokerrokset koostuvat joukosta opittavia suodattimia (tai ytimiä), joilla on pieni leveys ja korkeus ja sama syvyys kuin syöttötilavuudella (3, jos syöttökerros on kuvasyöttö).
- Esimerkiksi, jos meidän on suoritettava konvoluutio kuvalle, jonka mitat ovat 34x34x3. Suodattimien mahdollinen koko voi olla axax3, jossa 'a' voi olla mitä tahansa 3, 5 tai 7, mutta pienempi kuin kuvan koko.
- Eteenpäin siirron aikana liu'utamme kutakin suodatinta koko syöttötilavuuden poikki askel askeleelta, missä jokainen vaihe kutsutaan askel (jonka arvo voi olla 2, 3 tai jopa 4 korkeaulotteisille kuville) ja laske pistetulo ytimen painojen ja korjaustiedoston välillä syöttötilavuudesta.
- Kun liu'utamme suodattimia, saamme jokaiselle suodattimelle 2-D-ulostulon ja pinoamme ne yhteen, jolloin saadaan ulostulotilavuus, jonka syvyys on yhtä suuri kuin suodattimien lukumäärä. Verkko oppii kaikki suodattimet.
ConvNets-verkkojen rakentamiseen käytetyt tasot
Täydellinen Convolution Neural Networks -arkkitehtuuri tunnetaan myös nimellä covnet. Covnets on kerrosten sarja, ja jokainen kerros muuntaa yhden tilavuuden toiseksi differentioituvan funktion avulla.
Kerrosten tyypit: tietojoukot
Otetaan esimerkki suorittamalla covnets kuvasta, jonka mitat ovat 32 x 32 x 3.
- Syöttötasot: Se on kerros, jossa annamme syötteen mallillemme. CNN:ssä syöte on yleensä kuva tai kuvasarja. Tämä kerros sisältää kuvan raakasyötteen, jonka leveys on 32, korkeus 32 ja syvyys 3.
- Konvoluutiokerrokset: Tämä on kerros, jota käytetään ominaisuuden poimimiseen syöttötietojoukosta. Se käyttää syöttökuviin joukon opittavia suodattimia, jotka tunnetaan nimellä ytimet. Suodattimet/ytimet ovat pienempiä matriiseja, yleensä 2×2, 3×3 tai 5×5 muotoisia. se liukuu syötetyn kuvadatan yli ja laskee pistetulon ytimen painon ja vastaavan syötetyn kuvapaikan välillä. Tämän kerroksen tulosta kutsutaan ominaisuuskartoiksi. Oletetaan, että käytämme yhteensä 12 suodatinta tälle kerrokselle, saamme lähtötilavuuden mitat 32 x 32 x 12.
- Aktivointikerros: Lisäämällä aktivointifunktion edellisen kerroksen ulostuloon aktivointikerrokset lisäävät verkkoon epälineaarisuutta. se soveltaa elementtikohtaista aktivointifunktiota konvoluutiokerroksen ulostuloon. Jotkut yleiset aktivointitoiminnot ovat jatkaa : max(0, x), Hämärä , Vuotava RELU jne. Äänenvoimakkuus pysyy ennallaan, joten lähtötilavuuden mitat ovat 32 x 32 x 12.
- Poolauskerros: Tämä kerros lisätään ajoittain kovnetteihin ja sen päätehtävänä on pienentää tilavuuden kokoa, mikä tekee laskemisesta nopeaa vähentää muistia ja myös estää ylisovituksen. Kaksi yleistä poolauskerrostyyppiä ovat max pooling ja keskimääräinen yhdistäminen . Jos käytämme max poolia, jossa on 2 x 2 suodatinta ja askel 2, tuloksena oleva tilavuus on kooltaan 16 x 16 x 12.
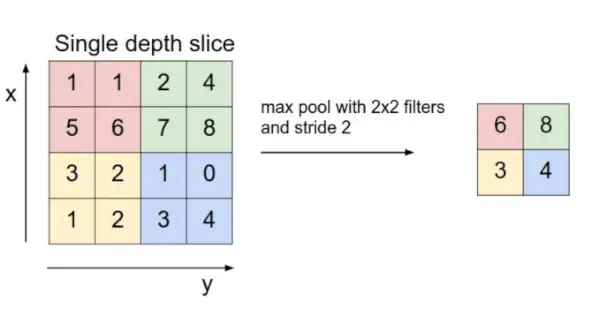
Kuvan lähde: cs231n.stanford.edu
- Tasoitus: Tuloksena saadut piirrekartat litistetään yksiulotteiseksi vektoriksi konvoluutio- ja yhdistämiskerrosten jälkeen, jotta ne voidaan siirtää täysin linkitetyksi kerrokseksi luokittelua tai regressiota varten.
- Täysin yhdistetyt kerrokset: Se ottaa syötteen edelliseltä tasolta ja laskee lopullisen luokittelu- tai regressiotehtävän.
Kuvan lähde: cs231n.stanford.edu
- Tulostuskerros: Täysin yhdistettyjen kerrosten tulos syötetään sitten logistiikkafunktioon luokitustehtäviä, kuten sigmoid tai softmax, varten, joka muuntaa kunkin luokan lähdön kunkin luokan todennäköisyyspisteiksi.
Esimerkki:
Tarkastellaan kuvaa ja käytetään konvoluutiokerrosta, aktivointikerrosta ja poolauskerroksen toimintoa sisäisen ominaisuuden poistamiseksi.
Syötä kuva:
Syötä kuva
Vaihe:
- tuoda tarvittavat kirjastot
- aseta parametri
- määritellä ydin
- Lataa kuva ja piirrä se.
- Alusta kuva uudelleen
- Käytä konvoluutiokerroksen operaatiota ja piirrä tuloskuva.
- Käytä aktivointikerroksen toimintoa ja piirrä tuloskuva.
- Käytä poolauskerroksen toimintoa ja piirrä tulostekuva.
Python 3
kuinka ladata youtube-videoita vlc
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
>
Lähtö :

Alkuperäinen harmaasävykuva
Lähtö
muuten java
Konvoluutiohermoverkkojen (CNN) edut:
- Hyvä havaitsemaan kuvioita ja ominaisuuksia kuvista, videoista ja äänisignaaleista.
- Kestävä käännökseen, kiertoon ja skaalausinvarianssiin.
- Kokonaisvaltainen koulutus, ei tarvetta manuaaliseen ominaisuuksien purkamiseen.
- Pystyy käsittelemään suuria tietomääriä ja saavuttamaan suuren tarkkuuden.
Konvoluutiohermoverkkojen (CNN:t) haitat:
- Harjoittelu on laskennallisesti kallista ja vaatii paljon muistia.
- Voi olla altis ylisovitukselle, jos ei käytetä tarpeeksi dataa tai kunnollista säätämistä.
- Vaatii suuria määriä merkittyjä tietoja.
- Tulkittavuus on rajallista, on vaikea ymmärtää, mitä verkko on oppinut.
Usein kysytyt kysymykset (FAQ)
1: Mikä on konvoluutiohermoverkko (CNN)?
Convolutional Neural Network (CNN) on eräänlainen syväoppiva hermoverkko, joka sopii hyvin kuva- ja videoanalyysiin. CNN:t käyttävät useita konvoluutio- ja yhdistämiskerroksia poimiakseen ominaisuuksia kuvista ja videoista ja käyttävät sitten näitä ominaisuuksia kohteiden tai kohtausten luokitteluun tai havaitsemiseen.
2: Miten CNN:t toimivat?
CNN:t toimivat soveltamalla sarjaa konvoluutio- ja yhdistämällä kerroksia syötekuvaan tai -videoon. Konvoluutiokerrokset poimivat piirteitä syötteestä liu'uttamalla pienen suodattimen tai ytimen kuvan tai videon päälle ja laskemalla pistetulon suodattimen ja syötteen välillä. Yhdistelmätasot laskevat sitten konvoluutiokerrosten ulostuloa pienentääkseen datan ulottuvuutta ja tehdäkseen siitä laskennallisesti tehokkaamman.
3: Mitä yleisiä aktivointitoimintoja käytetään CNN:issä?
Joitakin yleisiä CNN:issä käytettyjä aktivointitoimintoja ovat:
- Rectified Linear Unit (ReLU): ReLU on kyllästämätön aktivointitoiminto, joka on laskennallisesti tehokas ja helppo harjoitella.
- Leaky Rectified Linear Unit (Leaky ReLU): Leaky ReLU on ReLU:n muunnos, joka sallii pienen määrän negatiivista gradienttia virrata verkon läpi. Tämä voi auttaa estämään verkon kuolemisen harjoituksen aikana.
- Parametric Rectified Linear Unit (PReLU): PReLU on Leaky ReLU:n yleistys, joka mahdollistaa negatiivisen gradientin kaltevuuden oppimisen.
4: Mikä on useiden konvoluutiokerrosten käytön tarkoitus CNN:ssä?
Useiden konvoluutiokerrosten käyttäminen CNN:ssä sallii verkon oppia yhä monimutkaisempia ominaisuuksia syötekuvasta tai videosta. Ensimmäiset konvoluutiokerrokset oppivat yksinkertaisia ominaisuuksia, kuten reunoja ja kulmia. Syvemmät konvoluutiokerrokset oppivat monimutkaisempia piirteitä, kuten muotoja ja esineitä.
5: Mitä yleisiä regularisointitekniikoita käytetään CNN:issä?
Regularisointitekniikoita käytetään estämään CNN-verkkoja sovittamasta liikaa harjoitustietoja. Joitakin yleisiä CNN:issä käytettyjä regularisointitekniikoita ovat:
- Dropout: Dropout pudottaa satunnaisesti neuronit verkosta harjoituksen aikana. Tämä pakottaa verkon oppimaan tehokkaampia ominaisuuksia, jotka eivät ole riippuvaisia yhdestäkään neuronista.
- L1-regulointi: L1-regulointi regularisoi painojen itseisarvo verkossa. Tämä voi auttaa vähentämään painojen määrää ja tehostamaan verkkoa.
- L2-regulointi: L2-regulointi regularisoi verkon painojen neliö. Tämä voi myös auttaa vähentämään painojen määrää ja tehostamaan verkkoa.
6: Mitä eroa on konvoluutiokerroksen ja poolauskerroksen välillä?
Konvoluutiokerros poimii piirteitä syötekuvasta tai -videosta, kun taas poolauskerros alentaa konvoluutiokerrosten tulosteita. Konvoluutiotasot käyttävät useita suodattimia ominaisuuksien poimimiseen, kun taas poolitustasot käyttävät erilaisia tekniikoita datan alasnäytteen ottamiseen, kuten maksimivarausta ja keskimääräistä yhdistämistä.