Linux uniq -komentoa käytetään poistamaan kaikki toistuvat rivit tiedostosta. Sitä voidaan myös käyttää näyttämään minkä tahansa sanan lukumäärä, vain toistuvat rivit, ohittamaan merkit ja vertailemaan tiettyjä kenttiä. Se on yksi useimmin käytetyistä komennoista Linux järjestelmä. Sitä käytetään usein kanssa lajittelukomento koska se vertaa vierekkäisiä merkkejä. Se hylkää kaikki identtiset rivit ja kirjoittaa tulosteen.
Syntaksi:
uniq [OPTION]... [INPUT [OUTPUT]]
Vaihtoehdot:
Joitakin hyödyllisiä uniq-komennon komentorivivaihtoehtoja ovat seuraavat:
-c, --count: se asettaa rivien etuliitteen esiintymien lukumäärän mukaan.
-d, --toisti: sitä käytetään kahden rivin tulostamiseen, yksi jokaiselle ryhmälle.
-D: Sitä käytetään kaikkien päällekkäisten rivien tulostamiseen.
--kaikki-toistuva[=TAPA]: Se on melko samanlainen kuin '-D'-vaihtoehto, ero molempien vaihtoehtojen välillä on, että se sallii ryhmien erottamisen tyhjällä rivillä.
powershell suurempi tai yhtä suuri
-f, --skip-fields=N: Sitä käytetään välttämään ensimmäisen N kentän vertailua.
--ryhmä[=TAPA]: Sitä käytetään näyttämään kaikki kohteet ja erottaa ryhmät tyhjällä rivillä.
-i, --ignore-case: Sitä käytetään erojen huomiotta jättämiseen vertailussa.
alamerkkijono bashissa
-s, --skip-chars=N: Sitä käytetään välttämään ensimmäisen N merkin vertailua.
-u, --ainutlaatuinen: sitä käytetään ainutlaatuisten viivojen tulostamiseen.
-z, --nollapäätteinen: Sitä käytetään rivinerotin on NUL eikä rivinvaihtotila.
-w, --check-chars=N: Sitä käytetään vertaamaan enintään N merkkiä riveillä.
--auta: Sitä käytetään ohjedokumenttien näyttämiseen.
--versio: Sitä käytetään versiotietojen näyttämiseen.
Esimerkkejä uniq-komennosta
Katsotaanpa seuraavat esimerkit uniq-komennosta:
- Poista toistuvat rivit
- laskea sanan esiintymisten lukumäärä
- Näytä toistuvat rivit
- Näytä ainutlaatuiset rivit
- Ohita merkit vertailussa
- Ohita vertailussa olevat kentät
Poista toistuvat rivit
Poistaaksesi toistuvat rivit tiedostosta, suorita uniq-peruskomento seuraavasti:
kuinka löytää näytön koko
sort dupli.txt | uniq
Yllä oleva komento poistaa päällekkäiset rivit tiedostosta 'dupli.txt'. Harkitse alla olevaa tulosta:
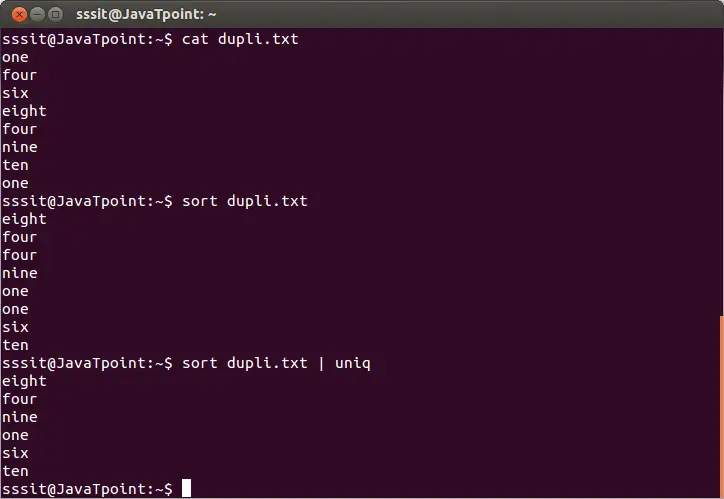
Yllä olevasta lähdöstä toistuvat sanat ohitetaan.
Laske sanan esiintymiskerrat
Voimme laskea sanan esiintymisten määrän käyttämällä uniq-komentoa. Vaihtoehtoa '-c' käytetään sanan laskemiseen. Suorita se seuraavasti:
sort dupli.txt | uniq -c
Yllä oleva komento laskee sanat, jotka tulevat 'dupli.txt'-tiedostoon. Harkitse alla olevaa tulosta:

Yllä olevasta lähdöstä komento 'sort dupli.txt | uniq -c' laskee kuinka monta kertaa sana toistuu.
Näytä toistuvat rivit
Vaihtoehtoa '-d' käytetään näyttämään vain toistetut rivit. Se näyttää vain rivit, jotka ovat useammin kuin kerran tiedostossa, ja kirjoittaa tulosteen vakiotulostukseen. Harkitse alla olevaa komentoa:
aakkosten numerointi
sort dupli.txt | uniq -d
Yllä oleva komento näyttää vain toistuvat rivit. Harkitse alla olevaa tulosta:

Näytä ainutlaatuiset rivit
Vaihtoehtoa '-u' käytetään näyttämään vain yksilölliset rivit (jotka eivät toistu). Se näyttää vain rivit, jotka esiintyvät vain kerran, ja kirjoittaa tuloksen vakiotulostukseen. Harkitse alla olevaa komentoa:
sort dupli.txt | uniq -u
Yllä oleva komento näyttää vain yksilölliset rivit tiedostosta 'dupli.txt'. Harkitse alla olevaa tulosta:
javan palautusjoukko

Ohita merkit vertailussa
'-s'-vaihtoehtoa käytetään huomioimaan merkit vertailussa. Se jättää huomioimatta määritetyn määrän merkkejä ja näyttää tuloksen vakiotulostuksessa. Harkitse alla olevaa komentoa:
sort dupli.txt | uniq -s 2
Yllä oleva komento jättää huomioimatta kaksi ensimmäistä merkkiä verrattuna tiedostoon 'dupli.txt'. Harkitse alla olevaa tulosta:

Ohita vertailussa olevat kentät
Vaihtoehtoa '-f' käytetään kenttien huomiotta jättämiseen. Harkitse alla olevaa komentoa:
uniq -f 2 dupli2.txt
Yllä oleva komento ei vertaa kahta ensimmäistä kenttää tiedostosta 'dupli2.txt'. Harkitse alla olevaa tulosta:

Yllä olevasta lähdöstä kaksi ensimmäistä kenttää ohitetaan, ja loput kentät verrataan tiedostosta 'dupli2.txt'.