Python on loistava kieli tietojen analysointiin ensisijaisesti fantastisen tietokeskeisen ekosysteemin vuoksi Python paketteja. Pandat on yksi näistä paketeista ja helpottaa tietojen tuontia ja analysointia paljon.
Pandas DataFrame tarkoittaa()
Pandat dataframe.mean() funktio palauttaa pyydetyn akselin arvojen keskiarvon. Jos menetelmää käytetään pandassarjan objektiin, menetelmä palauttaa skalaariarvon, joka on kaikkien havaintojen keskiarvo. Pandas Dataframe . Jos menetelmää käytetään Pandas Dataframe -objektiin, menetelmä palauttaa a Panda-sarja objekti, joka sisältää arvojen keskiarvon määritetyn akselin yli.
Syntaksi: DataFrame.mean(akseli = 0, skipna = tosi, taso = ei mitään, numeric_only = epätosi, **kwargs)
Parametrit:
- akseli: {indeksi (0), sarakkeet (1)}
- Tilaus : Sulje pois NA/nolla-arvot tulosta laskettaessa
- taso : Jos akseli on MultiIndex (hierarkkinen), laske tiettyä tasoa pitkin, jolloin se romahtaa sarjaksi
- vain numeerinen: Sisällytä vain float-, int- ja boolen sarakkeet. Jos Ei mitään, yrittää käyttää kaikkea ja käyttää vain numeerista tietoa. Ei käytössä sarjassa.
Palautukset: tarkoittaa: Sarja tai DataFrame (jos taso on määritetty)
merkkijonotaulukko c-kielellä
Pandas DataFrame.mean() Esimerkkejä
Esimerkki 1:
Käytä mean()-funktiota löytääksesi kaikkien havaintojen keskiarvon indeksiakselilla.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 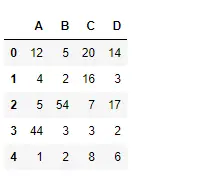
Käytämme Dataframe.mean()-funktiota löytääksesi keskiarvon indeksiakselin yli.
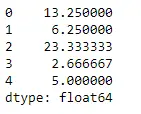
Python # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
Lähtö:
Esimerkki 2:
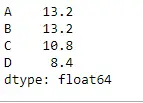
Käytä mean()-funktiota tietokehyksessä, jossa ei ole arvoja. Etsi myös keskiarvo sarakkeen akselin yli.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> Lähtö: