Mikä on LRU-välimuisti?
Välimuistin korvausalgoritmit on suunniteltu tehokkaasti korvaamaan välimuisti, kun tila on täynnä. The Vähiten käytetty (LRU) on yksi näistä algoritmeista. Kuten nimestä voi päätellä, kun välimuisti on täynnä, LRU poimii vähiten käytetyt tiedot ja poistaa ne tehdäkseen tilaa uusille tiedoille. Välimuistissa olevien tietojen prioriteetti muuttuu näiden tietojen tarpeen mukaan, eli jos jotakin dataa noudetaan tai päivitetään äskettäin, näiden tietojen prioriteetti muutetaan ja asetetaan korkeimpaan prioriteettiin, ja datan prioriteetti laskee, jos se jää käyttämättä toimintojen jälkeen.
Sisällysluettelo
- Mikä on LRU-välimuisti?
- Toiminnot LRU-välimuistissa:
- LRU-välimuistin toiminta:
- Tapoja ottaa LRU-välimuisti käyttöön:
- LRU-välimuistin toteutus jonon ja tiivistyksen avulla:
- LRU-välimuistin toteutus käyttämällä kaksoislinkitettyä luetteloa ja tiivistystä:
- LRU-välimuistin toteutus Deque & Hashmapin avulla:
- LRU-välimuistin toteutus Stack & Hashmapin avulla:
- LRU-välimuisti käyttämällä laskurin toteutusta:
- LRU-välimuistin toteutus Lazy Updatesin avulla:
- LRU-välimuistin monimutkaisuusanalyysi:
- LRU-välimuistin edut:
- LRU-välimuistin haitat:
- LRU-välimuistin reaalimaailman sovellus:
LRU Algoritmi on tavallinen ongelma ja se voi vaihdella tarpeen mukaan esimerkiksi käyttöjärjestelmissä LRU Sillä on ratkaiseva rooli, koska sitä voidaan käyttää sivun vaihtoalgoritmina sivuvirheiden minimoimiseksi.
Toiminnot LRU-välimuistissa:
- LRUCache (kapasiteetti c): Alusta LRU-välimuisti positiivisella kokokapasiteetilla c.
- saada (avain) : Palauttaa avaimen ' k' jos se on välimuistissa, muuten se palauttaa -1. Päivittää myös LRU-välimuistin tietojen prioriteetin.
- laittaa (avain, arvo): Päivitä avaimen arvo, jos se on olemassa. Muussa tapauksessa lisää avain-arvo-pari välimuistiin. Jos avainten määrä ylitti LRU-välimuistin kapasiteetin, hylkää viimeksi käytetty avain.
LRU-välimuistin toiminta:
Oletetaan, että meillä on LRU-välimuisti, jonka kapasiteetti on 3, ja haluaisimme suorittaa seuraavat toiminnot:
- Laita (avain=1, arvo=A) välimuistiin
- Laita (avain=2, arvo=B) välimuistiin
- Laita (avain=3, arvo=C) välimuistiin
- Hae (avain=2) välimuistista
- Hae (avain=4) välimuistista
- Laita (avain=4, arvo=D) välimuistiin
- Laita (avain=3, arvo=E) välimuistiin
- Hae (avain=4) välimuistista
- Laita (avain=1, arvo=A) välimuistiin
Yllä olevat toiminnot suoritetaan peräkkäin alla olevan kuvan mukaisesti:
Yksityiskohtainen selitys jokaisesta toiminnasta:
- Laita (avain 1, arvo A) : Koska LRU-välimuistin kapasiteetti on tyhjä = 3, vaihtoa ei tarvita ja laitamme {1 : A} yläosaan, eli {1 : A} on korkein prioriteetti.
- Laita (avain 2, arvo B) : Koska LRU-välimuistin kapasiteetti on tyhjä = 2, vaihtoa ei enää tarvita, mutta nyt {2 : B}:lla on korkein prioriteetti ja prioriteetti {1 : A} pienenee.
- Laita (avain 3, arvo C) : Välimuistissa on silti 1 tyhjä tila, joten laita {3 : C} ilman vaihtoa, huomaa nyt, että välimuisti on täynnä ja nykyinen tärkeysjärjestys korkeimmasta pienimpään on {3:C}, {2:B }, {1:A}.
- Hanki (avain 2) : Nyt palauta arvo avain=2 tämän toiminnon aikana, koska myös avain=2 on käytössä, uusi prioriteettijärjestys on nyt {2:B}, {3:C}, {1:A}
- Hanki (avain 4): Huomaa, että avainta 4 ei ole välimuistissa, palaamme tälle toiminnolle '-1'.
- Laita (avain 4, arvo D) : Huomaa, että välimuisti on TÄYNNÄ. Käytä nyt LRU-algoritmia määrittääksesi, mikä avain on viimeksi käytetty. Koska {1:A} oli pienin prioriteetti, poista {1:A} välimuististamme ja laita {4:D} välimuistiin. Huomaa, että uusi prioriteettijärjestys on {4:D}, {2:B}, {3:C}
- Laita (avain 3, arvo E) : Koska avain=3 oli jo olemassa välimuistissa, jossa on arvo=C, joten tämä toiminto ei johda minkään avaimen poistamiseen, vaan se päivittää avain=3:n arvoksi ' JA' . Nyt uudeksi tärkeysjärjestykseksi tulee {3:E}, {4:D}, {2:B}
- Hanki (avain 4) : Palauta avain=4. Nyt uudeksi prioriteetiksi tulee {4:D}, {3:E}, {2:B}
- Laita (avain 1, arvo A) : Koska välimuistimme on TÄYNNÄ, käytä LRU-algoritmiamme määrittääksesi, mitä avainta on käytetty vähiten äskettäin, ja koska {2:B} oli vähiten prioriteetti, poista {2:B} välimuististamme ja laita {1:A} kätkö. Nyt uusi prioriteettijärjestys on {1:A}, {4:D}, {3:E}
Tapoja ottaa LRU-välimuisti käyttöön:
LRU-välimuisti voidaan toteuttaa useilla tavoilla, ja jokainen ohjelmoija voi valita erilaisen lähestymistavan. Alla on kuitenkin yleisesti käytettyjä lähestymistapoja:
- LRU käyttäen jonoa ja hajautustoimintoa
- LRU käyttää Kaksoislinkitetty luettelo + hajautus
- LRU käyttäen Deque
- LRU käyttämällä pinoa
- LRU käyttää Vastatoteutus
- LRU käyttäen Lazy Updates -päivityksiä
LRU-välimuistin toteutus jonon ja tiivistyksen avulla:
Käytämme kahta tietorakennetta LRU-välimuistin toteuttamiseen.
- Jonottaa toteutetaan kaksoislinkitetyn luettelon avulla. Jonon enimmäiskoko on yhtä suuri kuin käytettävissä olevien kehysten kokonaismäärä (välimuistin koko). Viimeksi käytetyt sivut ovat lähellä etuosaa ja vähiten käytetyt sivut lähellä takaosaa.
- Hash sivunumero avaimena ja vastaavan jonosolmun osoite arvona.
Kun sivuun viitataan, haluttu sivu voi olla muistissa. Jos se on muistissa, meidän on irrotettava luettelon solmu ja tuotava se jonon etupuolelle.
Jos tarvittava sivu ei ole muistissa, tuomme sen muistiin. Yksinkertaisesti sanottuna lisäämme uuden solmun jonon etuosaan ja päivitämme vastaavan solmun osoitteen hashissa. Jos jono on täynnä, eli kaikki kehykset ovat täynnä, poistamme solmun jonon takaosasta ja lisäämme uuden solmun jonon etupuolelle.
Kuva:
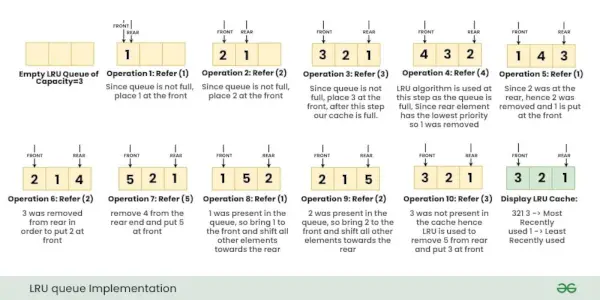
Mietitään operaatioita, Viittaa avain x kanssa LRU-välimuistissa: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Huomautus: Aluksi muistissa ei ole sivua.Alla olevat kuvat näyttävät vaihe vaiheelta yllä olevien toimintojen suorittamisen LRU-välimuistissa.
Algoritmi:
- Luo luokka LRUCache, joka ilmoittaa luettelosta tyypin int, järjestämättömän tyypin kartan
- LRUcachen referenssitoiminnossa
- Jos tätä arvoa ei ole jonossa, työnnä tämä arvo jonon eteen ja poista viimeinen arvo, jos jono on täynnä
- Jos arvo on jo olemassa, poista se jonosta ja työnnä se jonon eteen
- Kun näyttötoiminto tulostaa, LRUcache käyttäen jonoa alkaen edestä
Alla on yllä olevan lähestymistavan toteutus:
C++
k lähimmän naapurin algoritmi
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;>> // store references of key in cache> >unordered_map<>int>, list<>int>>::iteraattori> ma;>> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
tee javan aikana
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->sivuNumber = sivunumero;>> // Initialize prev and next as NULL> >temp->edellinen = temp->seuraava = NULL;>> return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->count = 0;>> // Number of frames that can be stored in memory> >queue->kehysten lukumäärä = kehysten lukumäärä;>> return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->kapasiteetti = kapasiteetti;>> // Create an array of pointers for referring queue nodes> >hash->matriisi>> malloc>(hash->kapasiteetti *>>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->taulukko[i] = NULL;>> return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->count == queue-> numberOframes;>> // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->takana == NULL;>> // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->edessä == jono->taka)> >queue->edessä = NULL;>> // Change rear and remove the previous rear> >QNode* temp = queue->takaosa;>> if> (queue->takana)>> >queue->taka->seuraava = NULL;>> free>(temp);> > >// decrement the number of full frames by 1> >queue->Kreivi--;>> // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->array[jono->taka->sivunumero] = NULL;>> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->seuraava = jono->etu;>> // If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->taka = jono->etu = lämpötila;>> // Else change the front> >{> >queue->etu->edellinen = lämpötila;>> > >// Add page entry to hash also> >hash->array[sivunumero] = temp;>> // increment number of full frames> >queue->count++;>> // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->taulukko[sivunumero];>> // the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->edessä) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->edellinen->seuraava = reqPage->seuraava;>> (reqPage->seuraava)>> // If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->takaosa) {> >queue->taka = reqPage->edellinen;>> > >// Put the requested page before current front> >reqPage->seuraava = jono->etu;>> // Change prev of current front> >reqPage->seuraava->edellinen = reqPage;>> // Change front to the requested page> >queue->edessä = reqPage;>> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->etu->sivunumero);>> (>'%d '>, q->etu->seuraava->sivunumero);>> (>'%d '>, q->etu->seuraava->seuraava->sivunumero);>> (>'%d '>, q->etu->seuraava->seuraava->seuraava->sivunumero);>> return> 0;> }> |
>
>
Java
java ja swing
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python 3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>doubleQueue;>> // store references of key in cache> >private> HashSet<>int>>hashSet;>> // maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();>> new> HashSet<>int>>();>> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
Javascript
usa kuinka monta kaupunkia
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
LRU-välimuistin toteutus käyttämällä kaksoislinkitettyä luetteloa ja tiivistystä :
Idea on hyvin yksinkertainen, eli jatka elementtien lisäämistä päähän.
- jos elementtiä ei ole luettelossa, lisää se luettelon päähän
- jos elementti on luettelossa, siirrä elementti päähän ja siirrä luettelon jäljellä olevaa elementtiä
Huomaa, että solmun prioriteetti riippuu kyseisen solmun etäisyydestä päähän. Mitä lähinnä solmu on päätä, sitä korkeampi prioriteetti sillä on. Joten kun välimuistin koko on täynnä ja meidän on poistettava jokin elementti, poistamme kaksoislinkitetyn luettelon hännän vieressä olevan elementin.
LRU-välimuistin toteutus Deque & Hashmapin avulla:
Deque-tietorakenne mahdollistaa lisäämisen ja poistamisen sekä edestä että päästä, tämä ominaisuus mahdollistaa LRU:n toteuttamisen, koska Front-elementti voi edustaa korkean prioriteetin elementtiä, kun taas loppuelementti voi olla matalan prioriteetin elementti, eli vähiten käytetty.
Työskentely:
kantataajuus vs laajakaista
- Hanki operaatio : Tarkistaa, onko avain olemassa välimuistin hash-kartassa ja seuraa alla olevia tapauksia dequessa:
- Jos avain löytyy:
- Esinettä pidetään äskettäin käytettynä, joten se siirretään dequen etupuolelle.
- Avaimeen liittyvä arvo palautetaan tuloksena
get>operaatio.- Jos avainta ei löydy:
- palauta -1 osoittamaan, ettei tällaista avainta ole.
- Laitteen toiminta: Tarkista ensin, onko avain jo olemassa välimuistin hash-kartassa ja seuraa alla olevia tapauksia dequessa
- Jos avain on olemassa:
- Avaimeen liittyvä arvo päivitetään.
- Esine on siirretty dequen etupuolelle, koska se on nyt viimeksi käytetty.
- Jos avainta ei ole:
- Jos välimuisti on täynnä, se tarkoittaa, että uusi kohde on lisättävä ja vähiten käytetty kohde on häätettävä. Tämä tehdään poistamalla kohde dequen lopusta ja vastaava merkintä hash-kartalta.
- Uusi avain-arvo-pari lisätään sitten sekä hash-karttaan että dequen etupuolelle osoittamaan, että se on viimeksi käytetty kohde
LRU-välimuistin toteutus Stack & Hashmapin avulla:
LRU (Least Recently Used) -välimuistin käyttöönotto pinon tietorakenteen ja hajautusjärjestelmän avulla voi olla hieman hankalaa, koska yksinkertainen pino ei tarjoa tehokasta pääsyä vähiten käytettyyn kohteeseen. Voit kuitenkin yhdistää pinon hajautuskarttaan saavuttaaksesi tämän tehokkaasti. Tässä on korkean tason lähestymistapa sen toteuttamiseen:
- Käytä Hash-karttaa : Hajautuskartta tallentaa välimuistin avainarvoparit. Avaimet kartoitetaan pinon vastaaviin solmuihin.
- Käytä pinoa : Pino säilyttää avainten järjestyksen niiden käytön perusteella. Vähiten käytetty esine on pinon alaosassa ja viimeksi käytetty esine on ylimpänä
Tämä lähestymistapa ei ole niin tehokas, joten sitä ei käytetä usein.
LRU-välimuisti käyttämällä laskurin toteutusta:
Jokaisella välimuistin lohkolla on oma LRU-laskuri, johon laskurin arvo kuuluu 0 - n-1} , tässä ' n ' edustaa välimuistin kokoa. Lohkon vaihdon aikana muutettu lohko muuttuu MRU-lohkoksi, jonka seurauksena sen laskurin arvo muuttuu n – 1:ksi. Laskuriarvot, jotka ovat suuremmat kuin avatun lohkon laskuriarvo, pienennetään yhdellä. Loput lohkot ovat muuttumattomia.
| Conterin arvo | Prioriteetti | Käytetty tila |
|---|---|---|
| 0 | Matala | Vähiten äskettäin käytetty |
| n-1 | Korkea | Viimeksi käytetty |
LRU-välimuistin toteutus Lazy Updatesin avulla:
LRU-välimuistin (Least Recently Used) käyttöönotto laiskoja päivityksiä käyttäen on yleinen tekniikka välimuistin toimintojen tehostamiseksi. Laiskot päivitykset sisältävät kohteiden käyttöjärjestyksen seuraamisen ilman, että koko tietorakennetta päivitetään välittömästi. Kun välimuisti puuttuu, voit päättää, suoritetaanko täydellinen päivitys joidenkin kriteerien perusteella.
LRU-välimuistin monimutkaisuusanalyysi:
- Aika monimutkaisuus:
- Put()-operaatio: O(1) eli uuden avainarvo-parin lisäämiseen tai päivittämiseen tarvittava aika on vakio
- Get()-operaatio: O(1) eli avaimen arvon saamiseen kuluva aika on vakio
- Aputila: O(N) missä N on välimuistin kapasiteetti.
LRU-välimuistin edut:
- Nopea pääsy : LRU-välimuistin tietojen käyttäminen kestää O(1) aikaa.
- Nopea päivitys : Kestää O(1) aikaa päivittää avainarvo-pari LRU-välimuistissa.
- Viimeksi käytettyjen tietojen nopea poistaminen : Kestää O(1) poistaa sen, jota ei ole viime aikoina käytetty.
- Ei lyömistä: LRU on vähemmän altis lyömiselle FIFO:han verrattuna, koska se ottaa huomioon sivujen käyttöhistorian. Se voi havaita, mitä sivuja käytetään usein, ja priorisoida ne muistin varaamiseksi, mikä vähentää sivuvirheiden ja levyn I/O-toimintojen määrää.
LRU-välimuistin haitat:
- Se vaatii suuren välimuistin tehokkuuden lisäämiseksi.
- Se vaatii lisätietorakenteen käyttöönottoa.
- Laitteistotuki on korkea.
- LRU:ssa virheiden havaitseminen on vaikeaa muihin algoritmeihin verrattuna.
- Sillä on rajoitettu hyväksyttävyys.
LRU-välimuistin reaalimaailman sovellus:
- Tietokantajärjestelmissä nopean kyselyn tulokset.
- Käyttöjärjestelmissä sivuvirheiden minimoimiseksi.
- Tekstieditorit ja IDE:t usein käytettyjen tiedostojen tai koodinpätkien tallentamiseen
- Verkkoreitittimet ja kytkimet käyttävät LRU:ta tietokoneverkon tehokkuuden lisäämiseen
- Kääntäjän optimoinnissa
- Tekstin ennustus ja automaattinen täydennystyökalut