A hash-taulukko on tietorakenne, joka mahdollistaa tietojen nopean lisäämisen, poistamisen ja hakemisen. Se toimii yhdistämällä avaimen taulukon indeksiin hash-funktiolla. Tässä artikkelissa toteutamme hajautustaulukon Pythonissa käyttämällä erillistä ketjutusta törmäysten käsittelemiseen.
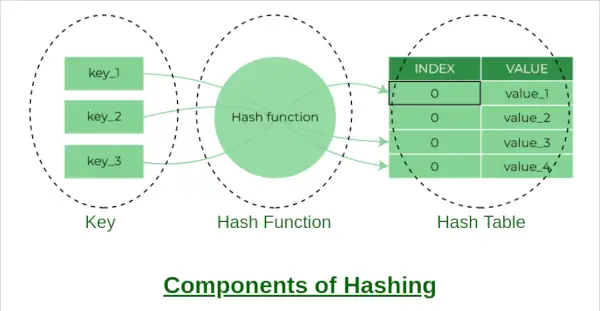
Hajautuksen osat
Erillinen ketjutus on tekniikka, jota käytetään käsittelemään törmäyksiä hash-taulukossa. Kun kaksi tai useampia avaimia liittyy samaan hakemistoon taulukossa, tallennamme ne linkitettyyn luetteloon kyseisessä hakemistossa. Tämän ansiosta voimme tallentaa useita arvoja samaan indeksiin ja silti pystyä hakemaan ne avaimellaan.
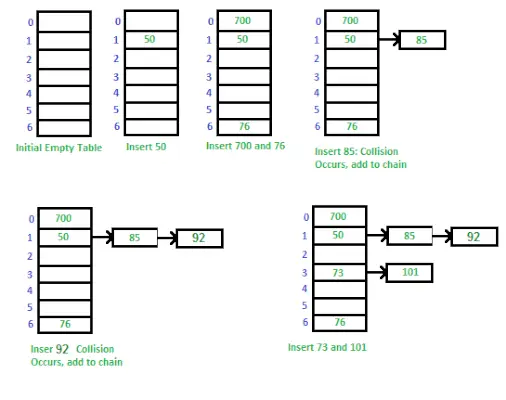
Tapa toteuttaa hash-taulukko erillisen ketjutuksen avulla
Tapa ottaa hash-taulukko käyttöön erillisen ketjutuksen avulla:
Luo kaksi luokkaa: ' Solmu 'ja' HashTable '.
' Solmu ' luokka edustaa solmua linkitetyssä luettelossa. Jokainen solmu sisältää avain-arvo-parin sekä osoittimen luettelon seuraavaan solmuun.
Python 3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> |
>
maapähkinä vs maapähkinä
>
HashTable-luokka sisältää taulukon, joka sisältää linkitetyt luettelot, sekä menetelmät tietojen lisäämiseksi, hakemiseksi ja poistamiseksi hash-taulukosta.
Python 3
class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> |
>
>
' __kuuma__ '-menetelmä alustaa hash-taulukon tietyllä kapasiteetilla. Se asettaa ' kapasiteettia 'ja' koko 'muuttujat ja alustaa taulukon arvoon 'Ei mitään'.
Seuraava menetelmä on ' _hash 'menetelmä. Tämä menetelmä ottaa avaimen ja palauttaa indeksin taulukkoon, johon avain-arvo-pari tulisi tallentaa. Käytämme Pythonin sisäänrakennettua hash-funktiota avaimen hajauttamiseen ja käytämme sitten modulo-operaattoria saadaksemme indeksin taulukkoon.
Python 3
def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> |
>
>
The 'lisää' menetelmä lisää avainarvo-parin hash-taulukkoon. Se vie indeksin, johon pari pitäisi tallentaa käyttämällä ' _hash 'menetelmä. Jos kyseisessä indeksissä ei ole linkitettyä luetteloa, se luo uuden solmun avain-arvo-parilla ja asettaa sen luettelon pääksi. Jos kyseisessä indeksissä on linkitetty luettelo, toista luetteloa, kunnes viimeinen solmu löytyy tai avain on jo olemassa, ja päivitä arvo, jos avain on jo olemassa. Jos se löytää avaimen, se päivittää arvon. Jos se ei löydä avainta, se luo uuden solmun ja lisää sen luettelon päähän.
Python 3
def> insert(>self>, key, value):> >index>=> self>._hash(key)> >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> |
valmistautua testiin mockito
>
>
java-verkkopalvelut
The Hae menetelmä hakee tiettyyn avaimeen liittyvän arvon. Se saa ensin indeksin, johon avain-arvo-pari tulisi tallentaa käyttämällä _hash menetelmä. Sitten se etsii avainta linkitetystä luettelosta kyseisessä hakemistossa. Jos se löytää avaimen, se palauttaa siihen liittyvän arvon. Jos se ei löydä avainta, se nostaa a KeyError .
Python 3
def> search(>self>, key):> >index>=> self>._hash(key)> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> >raise> KeyError(key)> |
>
>
The 'Poista' menetelmä poistaa avainarvo-parin hash-taulukosta. Se saa ensin indeksin, johon pari tulisi tallentaa käyttämällä ` _hash ` menetelmällä. Sitten se etsii avainta linkitetystä luettelosta kyseisessä hakemistossa. Jos se löytää avaimen, se poistaa solmun luettelosta. Jos se ei löydä avainta, se nostaa ` KeyError `.
Python 3
def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> |
>
>
'__str__' menetelmä, joka palauttaa tiivistetaulukon merkkijonoesityksen.
Python 3
def> __str__(>self>):> >elements>=> []> >for> i>in> range>(>self>.capacity):> >current>=> self>.table[i]> >while> current:> >elements.append((current.key, current.value))> >current>=> current.>next> >return> str>(elements)> |
>
>
Tässä on HashTable-luokan täydellinen toteutus:
Python 3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> > > class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> > >def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> > >def> insert(>self>, key, value):> >index>=> self>._hash(key)> > >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> > >def> search(>self>, key):> >index>=> self>._hash(key)> > >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> > >raise> KeyError(key)> > >def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> > >def> __len__(>self>):> >return> self>.size> > >def> __contains__(>self>, key):> >try>:> >self>.search(key)> >return> True> >except> KeyError:> >return> False> > > # Driver code> if> __name__>=>=> '__main__'>:> > ># Create a hash table with> ># a capacity of 5> >ht>=> HashTable(>5>)> > ># Add some key-value pairs> ># to the hash table> >ht.insert(>'apple'>,>3>)> >ht.insert(>'banana'>,>2>)> >ht.insert(>'cherry'>,>5>)> > ># Check if the hash table> ># contains a key> >print>(>'apple'> in> ht)># True> >print>(>'durian'> in> ht)># False> > ># Get the value for a key> >print>(ht.search(>'banana'>))># 2> > ># Update the value for a key> >ht.insert(>'banana'>,>4>)> >print>(ht.search(>'banana'>))># 4> > >ht.remove(>'apple'>)> ># Check the size of the hash table> >print>(>len>(ht))># 3> |
>
Cassidy Hutchinsonin koulutus
>Lähtö
True False 2 4 3>
Ajan ja tilan monimutkaisuus:
- The aika monimutkaisuus -lta lisää , Hae ja Poista Erillistä ketjutusta käyttävät menetelmät hash-taulukossa riippuvat hash-taulukon koosta, hajautustaulukon avainarvoparien määrästä ja linkitetyn luettelon pituudesta kussakin indeksissä.
- Olettaen, että hash-funktio on hyvä ja avaimet jakautuvat tasaisesti, näiden menetelmien oletettu aikamonimutkaisuus on O(1) jokaista operaatiota varten. Pahimmassa tapauksessa aika monimutkaisuus voi kuitenkin olla Päällä) , jossa n on avainarvo-parien määrä hash-taulukossa.
- On kuitenkin tärkeää valita hyvä hash-funktio ja sopiva koko hash-taulukolle törmäysten todennäköisyyden minimoimiseksi ja hyvän suorituskyvyn varmistamiseksi.
- The tilan monimutkaisuus Hajautustaulukon erillinen ketjuttaminen riippuu hash-taulukon koosta ja hajautustaulukkoon tallennettujen avainarvoparien määrästä.
- Hash-taulukko itse ottaa O(m) tila, jossa m on hash-taulukon kapasiteetti. Jokainen linkitetty luettelosolmu ottaa O(1) tilaa, ja linkitetyissä listoissa voi olla enintään n solmua, missä n on hash-taulukkoon tallennettujen avainarvoparien lukumäärä.
- Siksi koko tilan monimutkaisuus on O(m + n) .
Johtopäätös:
Käytännössä on tärkeää valita sopiva kapasiteetti hash-taulukolle tilankäytön ja törmäysten todennäköisyyden tasapainottamiseksi. Jos kapasiteetti on liian pieni, törmäysten todennäköisyys kasvaa, mikä voi aiheuttaa suorituskyvyn heikkenemistä. Toisaalta, jos kapasiteetti on liian suuri, hash-taulukko voi kuluttaa enemmän muistia kuin on tarpeen.