Pandat dataframe.corr() käytetään etsimään kaikkien Pythonin Pandas Dataframe -sarakkeiden sarakkeiden parillinen korrelaatio. Minkä tahansa NaN arvot suljetaan automaattisesti pois. Jos haluat ohittaa muut kuin numeeriset arvot, käytä parametria numeric_only = True. Tässä artikkelissa opimme DataFrame.corr()-menetelmästä Python .
Pandas DataFrame corr() -menetelmän syntaksi
Syntaksi: DataFrame.corr(self, method='pearson', min_periods=1, numeric_only = False)
Parametrit:
- menetelmä:
- pearson: standardi korrelaatiokerroin
- kendall: Kendall Tau -korrelaatiokerroin
- keihäsmies: Spearman rankkorrelaatio
- min_jaksot: Havaintojen vähimmäismäärä sarakeparia kohti, jotta tulos olisi kelvollinen. Tällä hetkellä saatavilla vain Pearsonin ja Spearmanin korrelaatiolle
- numeric_only : Käytetäänkö vain numeerisia arvoja vai ei. Se on oletusarvoisesti asetettu arvoon False.
Palautukset: count :y : DataFrame
Pandas Data Korrelaatiot corr() -menetelmä
Hyvä korrelaatio riippuu käytöstä, mutta on turvallista sanoa, että sinulla on vähintään 0,6 (tai -0,6), jotta sitä voidaan kutsua hyväksi korrelaatioksi. Yksinkertainen esimerkki korrelaatiosta Python .
Python 3
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
kytkinkotelo java
>
>
Lähtö
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Esimerkkitietokehyksen luominen
Datakehyksen 10 ensimmäisen rivin tulostaminen.
Huomautus: Muuttujan korrelaatio itsensä kanssa on 1. Saat linkin Koodissa käytettyyn CSV-tiedostoon napsauttamalla tässä
Python 3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Lähtö

Python Pandas DataFrame corr() -menetelmäesimerkkejä
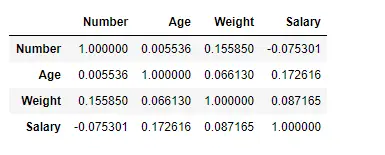
Etsi korrelaatio sarakkeiden välillä Pearsonin menetelmällä
Käytämme tässä corr()-funktiota korrelaation etsimiseen tietokehyksen sarakkeiden välillä käyttämällä 'Pearson'-menetelmää. Tietokehyksessä on vain neljä numeerista saraketta. Lähtö Dataframe voidaan tulkita kuten mille tahansa solulle, rivimuuttujan korrelaatio sarakemuuttujan kanssa on solun arvo. Kuten aiemmin mainittiin, muuttujan korrelaatio itsensä kanssa on 1. Tästä syystä kaikki diagonaaliarvot ovat 1,00.
Python 3
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
preity zinta
>
Lähtö
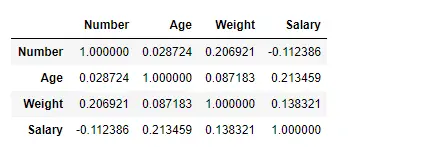
Etsi korrelaatio sarakkeiden välillä Kendall-menetelmällä
Käytä Pandasin df.corr()-funktiota löytääksesi korrelaation tietokehyksen sarakkeiden välillä käyttämällä kendall-menetelmää. Lähtö Dataframe voidaan tulkita kuten mille tahansa solulle, rivimuuttujan korrelaatio sarakemuuttujan kanssa on solun arvo. Kuten aiemmin mainittiin, muuttujan korrelaatio itsensä kanssa on 1. Tästä syystä kaikki diagonaaliarvot ovat 1,00.
Python 3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
>
>
Lähtö