IDENTITY-avainsana on SQL Serverin ominaisuus. Kun taulukon sarake määritetään identiteettiominaisuudella, sen arvo on automaattisesti luotu lisäarvo . Palvelin luo tämän arvon automaattisesti. Siksi emme voi syöttää arvoa manuaalisesti identiteettisarakkeeseen käyttäjänä. Näin ollen, jos merkitsemme sarakkeen identiteetiksi, SQL Server täyttää sen automaattisesti kasvavalla tavalla.
Syntaksi
Seuraavassa on syntaksi, joka havainnollistaa IDENTITY-ominaisuuden käyttöä SQL Serverissä:
IDENTITY[(seed, increment)]
Yllä olevat syntaksiparametrit selitetään alla:
Ymmärrämme tätä käsitettä yksinkertaisen esimerkin kautta.
Oletetaan, että meillä on Opiskelija ' pöytään, ja haluamme Opiskelijanumero luodaan automaattisesti. Meillä on alkava opiskelijatunnus 10 ja haluat lisätä sitä yhdellä jokaisella uudella tunnuksella. Tässä skenaariossa seuraavat arvot on määritettävä.
Siemen: 10
Lisäys: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
HUOMAUTUS: Vain yksi tunnistesarake on sallittu taulukkoa kohden SQL Serverissä.
SQL Server IDENTITY Esimerkki
Ymmärrämme kuinka voimme käyttää identiteettiominaisuutta taulukossa. Sarakkeen identiteettiominaisuus voidaan asettaa joko uuden taulukon luomisen yhteydessä tai sen luomisen jälkeen. Tässä näemme molemmat tapaukset esimerkein.
IDENTITY-ominaisuus uudella taulukolla
Seuraava käsky luo määritettyyn tietokantaan uuden taulukon, jossa on identiteettiominaisuus:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Seuraavaksi lisäämme tähän taulukkoon uuden rivin an OUTPUT lauseke, jolla näet automaattisesti luodun henkilötunnuksen:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
Tämän kyselyn suorittaminen näyttää seuraavan tuloksen:
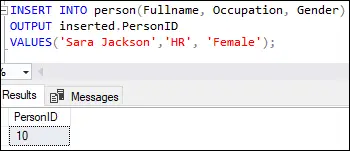
Tämä tulos osoittaa, että ensimmäinen rivi on lisätty arvolla kymmenen Henkilötunnus sarake taulukon määritelmän identiteettisarakkeen mukaisesti.
Lisätään toinen rivi riviin henkilö pöytä kuten alla:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Tämä kysely palauttaa seuraavan tuloksen:

Tämä tulos osoittaa, että henkilötunnus-sarakkeeseen on lisätty toinen rivi arvolla 11 ja kolmas rivi arvolla 12.
IDENTITY-ominaisuus olemassa olevan taulukon kanssa
Selitämme tämän käsitteen poistamalla ensin yllä olevan taulukon ja luomalla ne ilman identiteettiominaisuutta. Pudota taulukko suorittamalla alla oleva lauseke:
DROP TABLE person;
Seuraavaksi luomme taulukon alla olevalla kyselyllä:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Jos haluamme lisätä uuden sarakkeen identiteettiominaisuuden kanssa olemassa olevaan taulukkoon, meidän on käytettävä ALTER-komentoa. Alla oleva kysely lisää PersonID:n identiteettisarakkeeksi henkilötaulukkoon:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Arvon lisääminen identiteettisarakkeeseen nimenomaisesti
Jos lisäämme uuden rivin yllä olevaan taulukkoon määrittämällä identiteettisarakkeen arvon nimenomaisesti, SQL Server antaa virheilmoituksen. Katso alla oleva kysely:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
Tämän kyselyn suorittaminen aiheuttaa seuraavan virheen:

Jos haluat lisätä identiteettisarakkeen arvon nimenomaisesti, meidän on ensin asetettava IDENTITY_INSERT-arvo PÄÄLLE. Suorita seuraavaksi lisäystoiminto lisätäksesi uuden rivin taulukkoon ja aseta sitten IDENTITY_INSERT-arvo OFF. Katso alla oleva koodiskripti:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT PÄÄLLÄ antaa käyttäjien sijoittaa tietoja identiteettisarakkeisiin IDENTITY_INSERT POIS estää niitä lisäämästä arvoa tähän sarakkeeseen.
Koodikomentosarjan suorittaminen näyttää alla olevan tulosteen, jossa voimme nähdä, että henkilötunnus, jonka arvo on 14, on lisätty onnistuneesti.

IDENTITY-toiminto
SQL Server tarjoaa joitain identiteettitoimintoja taulukon IDENTITY-sarakkeiden käsittelyä varten. Nämä identiteettitoiminnot on lueteltu alla:
- @@IDENTITY-toiminto
- SCOPE_IDENTITY() -funktio
- IDENT_CURRENT Toiminto
- IDENTITY-toiminto
Katsotaanpa IDENTITY-funktioita joidenkin esimerkkien avulla.
@@IDENTITY-toiminto
@@IDENTITY on järjestelmän määrittämä funktio, joka näyttää viimeisen identiteettiarvon (suurin käytetty identiteettiarvo), joka on luotu taulukkoon IDENTITY-sarakkeelle samassa istunnossa. Tämä funktiosarake palauttaa käskyn luoman identiteettiarvon sen jälkeen, kun taulukkoon on lisätty uusi merkintä. Se palauttaa a TYHJÄ arvo, kun suoritamme kyselyn, joka ei luo IDENTITY-arvoja. Se toimii aina nykyisen istunnon puitteissa. Sitä ei voi käyttää etänä.
Esimerkki
Oletetaan, että henkilötaulukon nykyinen enimmäisidentiteettiarvo on 13. Nyt lisäämme samaan istuntoon yhden tietueen, joka lisää identiteettiarvoa yhdellä. Sitten käytämme @@IDENTITY-funktiota saadaksemme viimeisen samassa istunnossa luodun identiteettiarvon.
Tässä on koko koodiskripti:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
Komentosarjan suorittaminen palauttaa seuraavan tulosteen, jossa voimme nähdä, että suurin käytetty identiteettiarvo on 14.

SCOPE_IDENTITY() -funktio
SCOPE_IDENTITY() on järjestelmän määrittämä funktio näyttää viimeisimmän identiteettiarvon nykyisen soveltamisalan taulukossa. Tämä laajuus voi olla moduuli, liipaisin, toiminto tai tallennettu toimintosarja. Se on samanlainen kuin @@IDENTITY()-funktio, paitsi että tällä funktiolla on vain rajoitettu laajuus. SCOPE_IDENTITY-funktio palauttaa arvon NULL, jos suoritamme sen ennen lisäystoimintoa, joka luo arvon samassa laajuudessa.
Esimerkki
Alla oleva koodi käyttää sekä @@IDENTITY- että SCOPE_IDENTITY()-funktiota samassa istunnossa. Tämä esimerkki näyttää ensin viimeisen identiteettiarvon ja lisää sitten yhden rivin taulukkoon. Seuraavaksi se suorittaa molemmat identiteettitoiminnot.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
Koodin suorittaminen näyttää saman arvon nykyisessä istunnossa ja samanlaisen laajuuden. Katso alla oleva tulostekuva:

Nyt näemme esimerkin avulla, kuinka molemmat funktiot eroavat toisistaan. Ensin luodaan kaksi taulukkoa nimeltä työntekijä_tiedot ja osasto käyttämällä alla olevaa lausetta:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
Seuraavaksi luomme INSERT-triggerin työntekijä_data-taulukkoon. Tätä laukaisinta kutsutaan lisäämään rivi osastotaulukkoon aina, kun lisäämme rivin työntekijä_data-taulukkoon.
Alla oleva kysely luo liipaisimen oletusarvon lisäämiseksi 'SE' osastotaulukossa jokaisessa lisäyskyselyssä työntekijä_data-taulukossa:
teelusikallinen vs ruokalusikka
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
Kun olet luonut triggerin, lisäämme yhden tietueen työntekijä_data-taulukkoon ja näemme sekä @@IDENTITY- että SCOPE_IDENTITY()-funktioiden tulosteet.
INSERT INTO employee_data VALUES ('John Mathew');
Kyselyn suorittaminen lisää yhden rivin työntekijä_data-taulukkoon ja luo identiteettiarvon samassa istunnossa. Kun lisäyskysely on suoritettu työntekijä_data-taulukossa, se kutsuu automaattisesti liipaisimen yhden rivin lisäämiseksi osastotaulukkoon. Identiteetin siemenarvo on 1 työntekijän_tiedot ja 100 osastotaulukolle.
Lopuksi suoritamme alla olevat käskyt, jotka näyttävät tulosteen 100 SELECT @@IDENTITY -funktiolle ja 1 funktiolle SCOPE_IDENTITY, koska ne palauttavat identiteettiarvon vain samassa laajuudessa.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Tässä on tulos:

IDENT_CURRENT()-funktio
IDENT_CURRENT on järjestelmän määrittämä funktio näyttää viimeisimmän IDENTITY-arvon luotu tietylle taulukolle missä tahansa yhteydessä. Tämä funktio ei ota huomioon identiteettiarvon luovan SQL-kyselyn laajuutta. Tämä toiminto vaatii taulukon nimen, jolle haluamme saada identiteettiarvon.
Esimerkki
Voimme ymmärtää sen avaamalla ensin kaksi yhteysikkunaa. Lisäämme ensimmäiseen ikkunaan yhden tietueen, joka luo henkilötaulukkoon identiteettiarvon 15. Seuraavaksi voimme tarkistaa tämän identiteettiarvon toisessa yhteysikkunassa, jossa voimme nähdä saman lähdön. Tässä koko koodi:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
Yllä olevien koodien suorittaminen kahdessa eri ikkunassa näyttää saman identiteettiarvon.

IDENTITY()-funktio
IDENTITY()-funktio on järjestelmän määrittelemä funktio käytetään identiteettisarakkeen lisäämiseen uuteen taulukkoon . Tämä funktio eroaa IDENTITY-ominaisuudesta, jota käytämme CREATE TABLE- ja ALTER TABLE -käskyjen kanssa. Voimme käyttää tätä funktiota vain SELECT INTO -käskyssä, jota käytetään siirrettäessä tietoja taulukosta toiseen.
Seuraava syntaksi havainnollistaa tämän funktion käyttöä SQL Serverissä:
IDENTITY (data_type , seed , increment) AS column_name
Jos lähdetaulukossa on IDENTITY-sarake, SELECT INTO -komennolla muodostettu taulukko perii sen oletuksena. Esimerkiksi , olemme aiemmin luoneet taulukkohenkilön, jolla on identiteettisarake. Oletetaan, että luomme uuden taulukon, joka perii henkilötaulukon käyttämällä SELECT INTO -lauseita IDENTITY()-funktiolla. Siinä tapauksessa saamme virheilmoituksen, koska lähdetaulukossa on jo identiteettisarake. Katso alla oleva kysely:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
Yllä olevan käskyn suorittaminen palauttaa seuraavan virhesanoman:

Luodaan uusi taulukko ilman identiteettiominaisuutta käyttämällä alla olevaa käskyä:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Kopioi sitten tämä taulukko käyttämällä SELECT INTO -käskyä, joka sisältää IDENTITY-funktion seuraavasti:
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
Kun lauseke on suoritettu, voimme varmistaa sen käyttämällä sp_help komento, joka näyttää taulukon ominaisuudet.

Voit nähdä IDENTITY-sarakkeen HOUSUTTELUA ominaisuuksia määritettyjen ehtojen mukaisesti.
Jos käytämme tätä funktiota SELECT-käskyn kanssa, SQL Server näyttää seuraavan virhesanoman:
Viesti 177, taso 15, tila 1, rivi 2 IDENTITY-funktiota voidaan käyttää vain, kun SELECT-käskyssä on INTO-lause.
IDENTITY-arvojen uudelleenkäyttö
Emme voi käyttää uudelleen SQL Server -taulukon identiteettiarvoja. Kun poistamme minkä tahansa rivin identiteettisaraketaulukosta, identiteettisarakkeeseen syntyy aukko. Lisäksi SQL Server luo aukon, kun lisäämme uuden rivin identiteettisarakkeeseen ja lauseke epäonnistuu tai peruutetaan. Aukko osoittaa, että identiteettiarvot ovat kadonneet eikä niitä voida luoda uudelleen IDENTITY-sarakkeeseen.
Harkitse alla olevaa esimerkkiä ymmärtääksesi sen käytännössä. Meillä on jo henkilötaulukko, joka sisältää seuraavat tiedot:

Seuraavaksi luomme vielä kaksi taulukkoa nimeltä 'sijainti' , ja ' henkilö_asema ' käyttämällä seuraavaa lausetta:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
Seuraavaksi yritämme lisätä uuden tietueen henkilötaulukkoon ja määrittää heille aseman lisäämällä uuden rivin henkilö_sijaintitaulukkoon. Teemme tämän käyttämällä tapahtumailmoitusta seuraavasti:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
Yllä oleva tapahtumakoodin komentosarja suorittaa ensimmäisen insert-käskyn onnistuneesti. Mutta toinen lause epäonnistui, koska paikkataulukossa ei ollut paikkaa, jonka tunnus on kymmenen. Tästä syystä koko kauppa peruutettiin.
Koska henkilötunnus-sarakkeen suurin identiteettiarvo on 16, ensimmäinen insert-lause kulutti identiteettiarvon 17, ja sitten tapahtuma peruutettiin. Siksi, jos lisäämme seuraavan rivin Henkilö-taulukkoon, seuraava identiteettiarvo on 18. Suorita alla oleva käsky:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
Tarkistettuamme henkilötaulukon uudelleen, näemme, että juuri lisätty tietue sisältää identiteettiarvon 18.

Kaksi IDENTITY-saraketta yhdessä taulukossa
Teknisesti ei ole mahdollista luoda kahta identiteettisaraketta yhteen taulukkoon. Jos teemme tämän, SQL Server antaa virheen. Katso seuraava kysely:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
Kun suoritamme tämän koodin, näemme seuraavan virheen:

Voimme kuitenkin luoda kaksi identiteettisaraketta yhteen taulukkoon käyttämällä laskettua saraketta. Seuraava kysely luo taulukon, jossa on laskettu sarake, joka käyttää alkuperäistä identiteettisaraketta ja pienentää sitä yhdellä.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
Seuraavaksi lisäämme joitain tietoja tähän taulukkoon käyttämällä alla olevaa komentoa:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Lopuksi tarkistamme taulukon tiedot SELECT-käskyllä. Se palauttaa seuraavan tulosteen:

Näemme kuvasta, kuinka SecondID-sarake toimii toisena identiteettisarakkeena, joka pienenee kymmenellä aloitusarvosta 9990.
SQL Serverin IDENTITY-sarakkeen väärinkäsitykset
DBA-käyttäjällä on monia väärinkäsityksiä SQL Server -identiteettisarakkeista. Seuraavassa on luettelo yleisimmistä väärinkäsityksistä identiteettisarakkeista, jotka näkevät:
IDENTITY-sarake on UNIQUE: SQL Serverin virallisen dokumentaation mukaan identiteettiominaisuus ei voi taata sarakkeen arvon yksilöllisyyttä. Meidän on käytettävä PRIMARY KEY, UNIQUE rajoitusta tai UNIQUE-indeksiä sarakkeen yksilöllisyyden pakottamiseksi.
IDENTITY-sarake luo peräkkäisiä numeroita: Virallisessa dokumentaatiossa todetaan selvästi, että identiteettisarakkeessa määritetyt arvot voivat kadota tietokannan vian tai palvelimen uudelleenkäynnistyksen yhteydessä. Se voi aiheuttaa aukkoja identiteettiarvoon lisäyksen aikana. Aukko voidaan luoda myös, kun poistamme arvon taulukosta tai insert-lausetta palautetaan. Arvoja, jotka aiheuttavat aukkoja, ei voida käyttää enempää.
IDENTITY-sarake ei voi luoda automaattisesti olemassa olevia arvoja: Identiteettisarake ei voi luoda automaattisesti olemassa olevia arvoja, ennen kuin identiteettiominaisuus on siedetty uudelleen DBCC CHECKIDENT -komennolla. Sen avulla voimme säätää identiteettiominaisuuden siemenarvoa (rivin aloitusarvoa). Tämän komennon suorittamisen jälkeen SQL Server ei tarkista taulukossa jo olevia äskettäin luotuja arvoja vai ei.
IDENTITY-sarake PRIMARY KEY -avaimena riittää tunnistamaan rivin: Jos ensisijainen avain sisältää taulukon identiteettisarakkeen ilman muita yksilöllisiä rajoituksia, sarake voi tallentaa päällekkäisiä arvoja ja estää sarakkeen yksilöllisyyden. Kuten tiedämme, ensisijainen avain ei voi tallentaa päällekkäisiä arvoja, mutta identiteettisarake voi tallentaa kaksoiskappaleita; on suositeltavaa olla käyttämättä ensisijaista avainta ja identiteettiominaisuutta samassa sarakkeessa.
Väärän työkalun käyttäminen identiteettiarvojen palauttamiseksi lisäyksen jälkeen: On myös yleinen harhakäsitys siitä, että @@IDENTITY-, SCOPE_IDENTITY(), IDENT_CURRENT- ja IDENTITY()-funktioiden välisiä eroja ei tiedetä, jotta identiteettiarvo lisätään suoraan juuri suorittamastamme käskystä.
Ero SEQUENCE:n ja IDENTITY:n välillä
Käytämme sekä SEQUENCE- että IDENTITY-toimintoa automaattisten numeroiden luomiseen. Sillä on kuitenkin joitain eroja, ja tärkein ero on, että identiteetti on taulukosta riippuvainen, kun taas sekvenssi ei ole. Tehdään yhteenveto niiden eroista taulukkomuotoon:
| IDENTITY | SEKVENSSI |
|---|---|
| Identiteetti-ominaisuutta käytetään tietylle taulukolle, eikä sitä voida jakaa muiden taulukoiden kanssa. | DBA määrittää sekvenssiobjektin, joka voidaan jakaa useiden taulukoiden kesken, koska se on riippumaton taulukosta. |
| Tämä ominaisuus luo arvot automaattisesti aina, kun insert-käsky suoritetaan taulukossa. | Se käyttää NEXT VALUE FOR -lausetta seuraavan arvon luomiseen sekvenssiobjektille. |
| SQL Server ei palauta identiteettiominaisuuden sarakearvoa alkuperäiseen arvoonsa. | SQL Server voi nollata sekvenssiobjektin arvon. |
| Emme voi asettaa enimmäisarvoa identiteettiomaisuudelle. | Voimme asettaa sekvenssiobjektin maksimiarvon. |
| Se on otettu käyttöön SQL Server 2000:ssa. | Se on otettu käyttöön SQL Server 2012:ssa. |
| Tämä ominaisuus ei voi luoda identiteettiarvoa laskevassa järjestyksessä. | Se voi tuottaa arvoja laskevassa järjestyksessä. |
Johtopäätös
Tämä artikkeli antaa täydellisen yleiskatsauksen IDENTITY-ominaisuudesta SQL Serverissä. Täällä olemme oppineet kuinka ja milloin identiteettiominaisuutta käytetään, sen erilaiset toiminnot, väärinkäsitykset ja miten se eroaa sekvenssistä.