C/C++/Java-ohjelman muisti voidaan varata joko pinoon tai kasaan.
Edellytys: C-ohjelman muistiasettelu .
Pinon jako: Varaus tapahtuu vierekkäisille muistilohkoille. Kutsumme sitä pinomuistin varaukseksi, koska varaus tapahtuu funktiokutsupinossa. Varattavan muistin koko on kääntäjälle tiedossa ja aina kun funktiota kutsutaan, sen muuttujat saavat muistia pinoon. Ja aina kun funktiokutsu on ohi, muuttujien muisti puretaan. Tämä kaikki tapahtuu käyttämällä joitain ennalta määritettyjä rutiineja kääntäjässä. Ohjelmoijan ei tarvitse huolehtia muistin varaamisesta ja pinomuuttujien varausten purkamisesta. Tällaista muistin varausta kutsutaan myös väliaikaiseksi muistin varaukseksi, koska heti menetelmän suorittamisen päätyttyä kaikki menetelmään kuuluva data huuhdellaan pois pinosta automaattisesti. Tämä tarkoittaa, että kaikki pinomuistikaavioon tallennetut arvot ovat käytettävissä niin kauan kuin menetelmä ei ole suorittanut loppuun ja on parhaillaan käynnissä.
arraylist ja linkedlist
Avainkohdat:
- Se on väliaikainen muistinvarausjärjestelmä, jossa datajäsenet ovat käytettävissä vain, jos ne sisältänyt menetelmä ( ) on parhaillaan käynnissä.
- Se varaa tai purkaa muistin automaattisesti heti, kun vastaava menetelmä suorittaa suorituksensa.
- Saamme vastaavan Java-virheen. lang. StackOverFlowError kirjoittaja JVM , Jos pinomuisti on täynnä.
- Pinomuistin varaamista pidetään turvallisempana keon muistin varaamiseen verrattuna, koska tallennettuja tietoja voi käyttää vain omistajasäie.
- Muistin varaaminen ja varauksen purkaminen ovat nopeampia verrattuna keon muistin varaamiseen.
- Pinomuistissa on vähemmän tallennustilaa verrattuna kasamuistiin.
int main() { // All these variables get memory // allocated on stack int a; int b[10]; int n = 20; int c[n]; }>
Kasan allokointi: Muisti varataan ohjelmoijien kirjoittamien ohjeiden suorittamisen aikana. Huomaa, että nimikekolla ei ole mitään tekemistä kohteen kanssa muistivuoto voi tapahtua ohjelmassa.
Keon muistin varaus on edelleen jaettu kolmeen luokkaan: - Nämä kolme luokkaa auttavat meitä priorisoimaan keon muistiin tai muistiin tallennettavat tiedot (objektit). Roskakokoelma .
bin to bcd
- Nuori sukupolvi - Se on osa muistia, jossa kaikki uudet tiedot (objektit) tehdään varaamaan tilaa, ja aina kun tämä muisti on täynnä, loput tiedoista tallennetaan Roskakeräykseen.
- Vanha tai vanha sukupolvi - Tämä on Heap-muistin osa, joka sisältää vanhemmat dataobjektit, jotka eivät ole usein käytössä tai eivät ole käytössä ollenkaan.
- Pysyvä sukupolvi - Tämä on Heap-muistin osa, joka sisältää JVM:n metatiedot ajonaikaisille luokille ja sovellusmenetelmille.
Avainkohdat:
- Saamme vastaavan virheilmoituksen, jos kasatila on täysin täynnä, java. lang.OutOfMemoryError kirjoittanut JVM.
- Tämä muistinvarausmenetelmä eroaa pinotilan allokoinnista, tässä ei ole automaattista varausten purkamisominaisuutta. Meidän on käytettävä roskienkerääjää poistaaksesi vanhat käyttämättömät esineet, jotta voimme käyttää muistia tehokkaasti.
- Tämän muistin käsittelyaika (käyttöaika) on melko hidas verrattuna pinomuistiin.
- Keon muisti ei myöskään ole yhtä turvallinen säikeille kuin pinomuisti, koska Keon muistiin tallennetut tiedot näkyvät kaikille säikeille.
- Heap-muistin koko on huomattavasti suurempi verrattuna pinomuistiin.
- Keon muisti on käytettävissä tai se on olemassa niin kauan kuin koko sovellus (tai Java-ohjelma) on käynnissä.
int main() { // This memory for 10 integers // is allocated on heap. int *ptr = new int[10]; }> Yhdistelmäesimerkki molemmista muistinvarauksista javasta:
C++ #include using namespace std; int main() { int a = 10; // stored in stack int* p = new int(); // allocate memory in heap *p = 10; delete (p); p = new int[4]; // array in heap allocation delete[] p; p = NULL; // free heap return 0; }> Java class Emp { int id; String emp_name; public Emp(int id, String emp_name) { this.id = id; this.emp_name = emp_name; } } public class Emp_detail { private static Emp Emp_detail(int id, String emp_name) { return new Emp(id, emp_name); } public static void main(String[] args) { int id = 21; String name = 'Maddy'; Emp person_ = null; person_ = Emp_detail(id, name); } }> Python def main(): a = 10 # stored in stack p = None # declaring p variable p = 10 # allocating memory in heap del p # deleting memory allocation in heap p = [None] * 4 # array in heap allocation p = None # free heap return 0 if __name__ == '__main__': main()>
Javascript // Define the Emp class with id and emp_name properties class Emp { constructor(id, emp_name) { this.id = id; // Initialize id this.emp_name = emp_name; // Initialize emp_name } } // Create an instance of the Emp class const person = new Emp(21, 'Maddy'); // Initialize person with id 21 and emp_name 'Maddy' console.log(person); // Output the person object to the console> Seuraavassa on johtopäätökset, jotka teemme analysoituamme yllä olevaa esimerkkiä:
c-merkkijono taulukossa
- Kun aloitamme have-ohjelman suorittamisen, kaikki ajonaikaiset luokat tallennetaan Heap-muistitilaan.
- Sitten löydämme seuraavalta riviltä main()-metodin, joka on tallennettu pinoon ja kaikki sen primitiivi(tai local) ja viitemuuttuja Emp tyyppiä Emp_detail tallennetaan myös pinoon ja osoittaa vastaavaan objektiin. tallennettu Kasan muistiin.
- Sitten seuraava rivi kutsuu parametroitua rakentajaa Emp(int, String) main( ) -ohjelmasta ja se myös varautuu saman pinomuistilohkon yläosaan. Tämä tallentaa:
- Pinomuistin kutsutun objektin objektiviite.
- Alkuperäinen arvo ( Argumentin String emp_name viitemuuttuja osoittaa varsinaiseen merkkijonoon merkkijonovarannosta keon muistiin.
- Sitten päämenetelmä kutsuu jälleen staattista menetelmää Emp_detail(), jolle tehdään varaus pinomuistilohkoon edellisen muistilohkon päälle.
- Argumentin String emp_name viitemuuttuja osoittaa varsinaiseen merkkijonoon merkkijonovarannosta keon muistiin.
Argumentin String emp_name viitemuuttuja osoittaa varsinaiseen merkkijonoon merkkijonovarannosta keon muistiin.
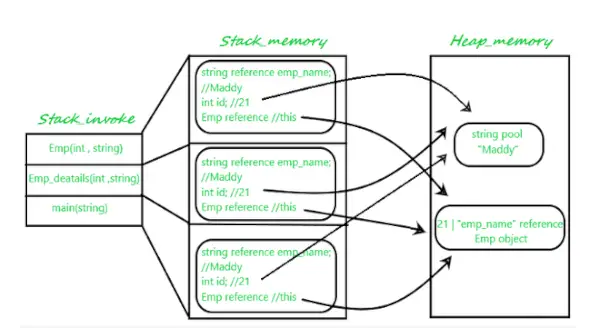
Kuva 1
Tärkeimmät erot pinon ja kasan allokaatioiden välillä
- Pinossa kääntäjä tekee varauksen ja varauksen purkamisen automaattisesti, kun taas kasassa ohjelmoijan on tehtävä se manuaalisesti.
- Kasan kehyksen käsittely on kalliimpaa kuin pinokehyksen käsittely.
- Muistin puuteongelma esiintyy todennäköisemmin pinossa, kun taas kasan muistin pääongelma on pirstoutuminen.
- Pinon kehysten käyttö on helpompaa kuin pinokehyksen, koska pinossa on pieni alue muistia ja se on välimuistiystävällinen, mutta jos kasakehykset ovat hajallaan koko muistissa, se aiheuttaa enemmän välimuistin menetyksiä.
- Pino ei ole joustava, varattu muistin kokoa ei voi muuttaa, kun taas pino on joustava, ja varattua muistia voidaan muuttaa.
- Keon kestoajan saaminen on enemmän kuin pino.
Vertailukaavio
| Parametri | PINO | PINO |
|---|---|---|
| Perus | Muisti on allokoitu vierekkäiseen lohkoon. | Muisti varataan missä tahansa satunnaisessa järjestyksessä. |
| Jakaminen ja kohdistamisen purkaminen | Automaattinen kääntäjän ohjeiden mukaan. | Ohjelmoijan käsikirja. |
| Kustannus | Vähemmän | Lisää |
| Toteutus | Helppo | Kovaa |
| Kirjautumisaika | Nopeammin | Hitaammin |
| Pääongelma | Muistin puute | Muistin pirstoutuminen |
| Viitepaikka | Erinomainen | Riittävä |
| Turvallisuus | Ketju turvallinen, tallennettuihin tietoihin pääsee vain omistaja | Ei säiettä turvassa, tallennetut tiedot näkyvät kaikille säikeille |
| Joustavuus | Kiinteä koko | Koon muuttaminen on mahdollista |
| Tietotyyppirakenne | Lineaarinen | Hierarkkinen |
| Suositeltava | Staattista muistin varausta suositellaan taulukossa. | Keon muistin varaus on suositeltu linkitetyssä luettelossa. |
| Koko | Pieni kuin kasa muisti. | Suurempi kuin pinomuisti. |