Excel-taulukot ovat erittäin vaistomaisia ja käyttäjäystävällisiä, mikä tekee niistä ihanteellisia suurten tietojoukkojen käsittelyyn jopa vähemmän tekniselle henkilölle. Jos etsit paikkoja, joissa voit oppia käsittelemään ja automatisoimaan Excel-tiedostoja käyttämällä Python , älä katso enää. Olet oikeassa paikassa.
Tässä artikkelissa opit käyttämään Pandat työskentelemään Excel-laskentataulukoiden kanssa. Tässä artikkelissa opimme:
- Lukea Excel-tiedosto Pandasin käyttäminen Pythonissa
- Pandan asentaminen ja tuonti
- Useiden Excel-arkkien lukeminen Pandalla
- Erilaisten Pandatoimintojen sovellus
Excel-tiedoston lukeminen Pandasin avulla Pythonissa
Pandan asennus
Pandasin asentamiseksi Pythonissa voimme käyttää seuraavaa komentoa komentokehotteessa:
pip install pandas>
Pandasin asentamiseksi Anacondaan voimme käyttää seuraavaa komentoa Anaconda Terminalissa:
conda install pandas>
Pandan tuonti
Ensinnäkin meidän on tuotava Pandas-moduuli, joka voidaan tehdä suorittamalla komento:
Python 3
import> pandas as pd> |
>
>
Syöttötiedosto: Oletetaan, että Excel-tiedosto näyttää tältä
Taulukko 1:

Arkki 1
Arkki 2:
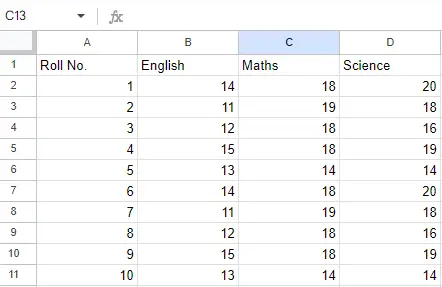
Arkki 2
Nyt voimme tuoda Excel-tiedoston Pandasin read_excel-funktiolla lukeaksemme Excel-tiedostoa Pandasin avulla Pythonissa. Toinen lauseke lukee tiedot Excelistä ja tallentaa ne pandas-tietokehykseen, jota edustaa muuttuja newData.
Python 3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Lähtö:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Useiden arkkien lataaminen Concat()-menetelmällä
Jos Excel-työkirjassa on useita taulukoita, komento tuo tiedot ensimmäisestä taulukosta. Tehdäksesi tietokehyksen kaikista työkirjan taulukoista, helpoin tapa on luoda eri tietokehykset erikseen ja sitten ketjuttaa ne. Read_excel-menetelmä käyttää argumentteja taulukon_nimi ja indeksin_cola, joissa voimme määrittää arkin, josta kehys tehdään, ja index_col määrittää otsikkosarakkeen, kuten alla on esitetty:
Esimerkki:
Kolmas lause ketjuttaa molemmat arkit. Nyt tarkistaaksesi koko tietokehyksen voimme yksinkertaisesti suorittaa seuraavan komennon:
Python 3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Lähtö:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Head()- ja Tail()-menetelmät Pandasissa
Jos haluat tarkastella 5 saraketta tietokehyksen ylä- ja alaosasta, voimme suorittaa komennon. Tämä pää() ja häntä () menetelmä ottaa myös argumentit numeroina näytettävien sarakkeiden lukumäärää varten.
Python 3
print>(newData.head())> print>(newData.tail())> |
>
>
Lähtö:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Shape() -menetelmä
The shape() -menetelmä voidaan käyttää datakehyksen rivien ja sarakkeiden määrän tarkastelemiseen seuraavasti:
Python 3
newData.shape> |
>
>
java yrittää saada kiinni
Lähtö:
(20, 3)>
Sort_values() -menetelmä Pandasissa
Jos jokin sarake sisältää numeerista tietoa, voimme lajitella sen sarakkeen avulla sort_values() menetelmä pandassa seuraavasti:
Python 3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Oletetaan nyt, että haluamme lajitellun sarakkeen viisi parasta arvoa, voimme käyttää head()-menetelmää tässä:
Python 3
sorted_column.head(>5>)> |
>
>
Lähtö:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Voimme tehdä sen millä tahansa tietokehyksen numeerisella sarakkeella alla olevan kuvan mukaisesti:
Python 3
newData[>'Maths'>].head()> |
>
>
Lähtö:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Pandas Describe() -menetelmä
Oletetaan nyt, että tietomme ovat enimmäkseen numeerisia. Voimme saada datakehyksen tilastotiedot, kuten keskiarvo, maksimi, min jne., käyttämällä kuvaile () alla olevan kuvan mukainen menetelmä:
Python 3
newData.describe()> |
>
>
Lähtö:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Tämä voidaan tehdä myös erikseen kaikille numeerisille sarakkeille seuraavalla komennolla:
Python 3
newData[>'English'>].mean()> |
>
>
Lähtö:
14.3>
Myös muita tilastotietoja voidaan laskea vastaavilla menetelmillä. Kuten Excelissä, myös kaavoja voidaan käyttää ja laskettuja sarakkeita voidaan luoda seuraavasti:
Python 3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
kuinka poistaa kehittäjätila käytöstä
Lähtö:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Tietokehyksen tietojen käsittelyn jälkeen voimme viedä tiedot takaisin Excel-tiedostoon menetelmällä to_excel. Tätä varten meidän on määritettävä Excel-tulostustiedosto, johon muunnetut tiedot kirjoitetaan, kuten alla:
Python 3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Lähtö:
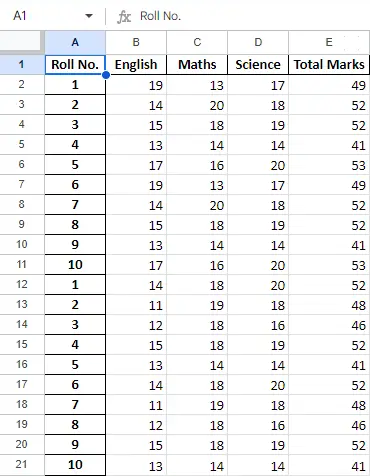
Viimeinen arkki