Yksi tärkeä näkökohta Koneoppiminen on mallin arviointi. Sinulla on oltava jokin mekanismi mallin arvioimiseksi. Tässä nämä suorituskykymittarit tulevat kuvaan, ja ne antavat meille käsityksen siitä, kuinka hyvä malli on. Jos olet perehtynyt joihinkin perusasioihin Koneoppiminen silloin sinun on täytynyt törmätä joihinkin näistä mittareista, kuten tarkkuus, tarkkuus, muistaminen, auc-roc jne., joita yleensä käytetään luokitustehtävissä. Tässä artikkelissa tutkimme perusteellisesti yhtä tällaista mittaria, joka on AUC-ROC-käyrä.
Sisällysluettelo
- Mikä on AUC-ROC-käyrä?
- AUC- ja ROC-käyrässä käytetyt keskeiset termit
- Herkkyyden, spesifisyyden, FPR:n ja kynnyksen välinen suhde.
- Miten AUC-ROC toimii?
- Milloin meidän tulisi käyttää AUC-ROC-arviointimetriikkaa?
- Spekuloidaan mallin suorituskykyä
- AUC-ROC-käyrän ymmärtäminen
- Toteutus kahdella eri mallilla
- Kuinka käyttää ROC-AUC:ta moniluokkaisessa mallissa?
- Usein kysyttyä AUC ROC -käyrästä koneoppimisessa
Mikä on AUC-ROC-käyrä?
AUC-ROC-käyrä eli Area Under the Receiver Operating Characteristic -käyrä on graafinen esitys binääriluokitusmallin suorituskyvystä eri luokituskynnyksillä. Sitä käytetään yleisesti koneoppimisessa arvioimaan mallin kykyä erottaa kaksi luokkaa, tyypillisesti positiivinen luokka (esim. sairauden esiintyminen) ja negatiivinen luokka (esim. sairauden puuttuminen).
Ymmärretään ensin näiden kahden termin merkitys ROC ja AUC .
- ROC : Vastaanottimen toimintaominaisuudet
- AUC : Käyrän alla oleva alue
Vastaanottimen toimintaominaisuuksien (ROC) käyrä
ROC on lyhenne sanoista Receiver Operating Characteristics, ja ROC-käyrä on graafinen esitys binääriluokitusmallin tehokkuudesta. Se piirtää todellisen positiivisen prosentin (TPR) vs. väärän positiivisen määrän (FPR) eri luokituskynnyksillä.
Käyrän alla oleva alue (AUC) käyrä:
AUC tarkoittaa aluetta käyrän alla, ja AUC-käyrä edustaa aluetta ROC-käyrän alla. Se mittaa binääriluokitusmallin yleistä suorituskykyä. Koska sekä TPR että FPR vaihtelevat välillä 0 - 1, alue on siis aina välillä 0 - 1, ja suurempi AUC-arvo tarkoittaa parempaa mallin suorituskykyä. Päätavoitteemme on maksimoida tämä alue, jotta meillä on korkein TPR ja alhaisin FPR annetulla kynnyksellä. AUC mittaa todennäköisyyttä, että malli antaa satunnaisesti valitulle positiiviselle esiintymälle suuremman ennustetun todennäköisyyden kuin satunnaisesti valitulle negatiiviselle ilmentymälle.
Se edustaa todennäköisyys joiden avulla mallimme voi erottaa kaksi tavoitteessamme olevaa luokkaa.
ROC-AUC-luokituksen arviointimetriikka
AUC- ja ROC-käyrässä käytetyt keskeiset termit
1. TPR ja FPR
Tämä on yleisin määritelmä, jonka olet kohdannut käyttäessäsi Googlea AUC-ROC. Periaatteessa ROC-käyrä on kaavio, joka näyttää luokitusmallin suorituskyvyn kaikilla mahdollisilla kynnyksillä (kynnys on tietty arvo, jonka ylittyessä sanot pisteen kuuluvan tiettyyn luokkaan). Käyrä piirretään kahden parametrin väliin
- TPR – Todellinen positiivinen korko
- FPR – Väärä positiivinen arvo
Ennen kuin ymmärrämme, TPR ja FPR katsokaamme nopeasti sekaannusmatriisi .
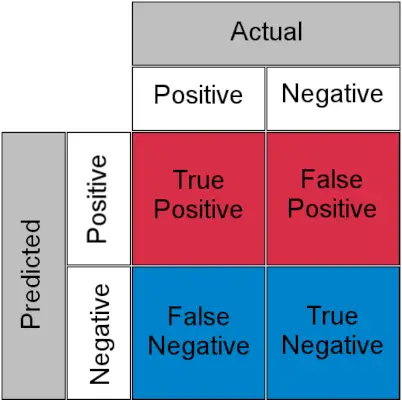
Hämmennysmatriisi luokitustehtävää varten
- Tosi positiivista : Todellinen positiivinen ja ennustettu positiiviseksi
- Todellinen negatiivinen : Todellinen negatiivinen ja ennustettu negatiiviseksi
- Väärin positiivinen (tyypin I virhe) : Todellinen negatiivinen, mutta ennustettu positiiviseksi
- Väärä negatiivinen (tyypin II virhe) : Todellinen positiivinen, mutta ennustettu negatiiviseksi
Yksinkertaisesti sanottuna voit kutsua Väärä positiivinen a väärä hälytys ja väärä negatiivinen a neiti . Katsotaanpa nyt mitä TPR ja FPR ovat.
2. Herkkyys / todellinen positiivinen nopeus / takaisinkutsu
Pohjimmiltaan TPR/Recall/Sensitivity on oikein tunnistettujen positiivisten esimerkkien suhde. Se edustaa mallin kykyä tunnistaa oikein positiiviset esiintymät ja se lasketaan seuraavasti:

Herkkyys/muistutus/TPR mittaa niiden todellisten positiivisten tapausten osuuden, jotka malli tunnistaa oikein positiivisiksi.
3. Väärä positiivinen arvo
FPR on virheellisesti luokiteltujen negatiivisten esimerkkien suhde.

4. Spesifisyys
Spesifisyys mittaa niiden todellisten negatiivisten esiintymien osuutta, jotka malli tunnistaa oikein negatiivisiksi. Se edustaa mallin kykyä tunnistaa oikein negatiiviset esiintymät

Ja kuten aiemmin todettiin, ROC on vain TPR:n ja FPR:n välinen käyrä kaikilla mahdollisilla kynnyksillä ja AUC on koko tämän ROC-käyrän alla oleva alue.
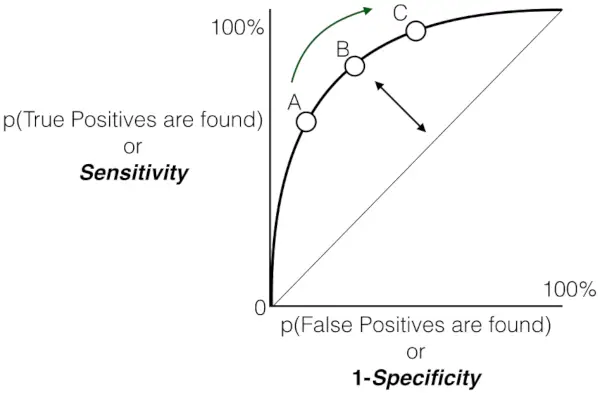
Herkkyys vs. väärä positiivinen korkokäyrä
Herkkyyden, spesifisyyden, FPR:n ja kynnyksen välinen suhde .
Herkkyys ja spesifisyys:
- Käänteinen suhde: herkkyydellä ja spesifisyydellä on käänteinen suhde. Kun yksi kasvaa, toisella on taipumus laskea. Tämä kuvastaa luontaista kompromissia todellisten positiivisten ja todellisten negatiivisten korkojen välillä.
- Viritys kynnyksen kautta: Säätämällä kynnysarvoa voimme hallita herkkyyden ja spesifisyyden välistä tasapainoa. Alemmat kynnykset johtavat korkeampaan herkkyyteen (enemmän todellisia positiivisia) spesifisyyden kustannuksella (enemmän vääriä positiivisia). Päinvastoin, kynnyksen nostaminen lisää spesifisyyttä (vähemmän vääriä positiivisia), mutta uhraa herkkyyden (enemmän vääriä negatiivisia).
Kynnys ja väärä positiivinen määrä (FPR):
- FPR ja spesifisyysyhteys: Väärä positiivinen määrä (FPR) on yksinkertaisesti spesifisyyden komplementti (FPR = 1 – spesifisyys). Tämä tarkoittaa suoraa yhteyttä niiden välillä: korkeampi spesifisyys tarkoittaa alhaisempaa FPR:ää ja päinvastoin.
- FPR:n muutokset TPR:n kanssa: Kuten huomasit, myös True Positive Rate (TPR) ja FPR ovat yhteydessä toisiinsa. TPR:n kasvu (enemmän todellisia positiivisia) johtaa yleensä FPR:n nousuun (enemmän vääriä positiivisia). Toisaalta TPR:n lasku (vähemmän todellisia positiivisia) johtaa FPR:n laskuun (vähemmän vääriä positiivisia)
Miten AUC-ROC toimii?
Tarkastelimme geometrista tulkintaa, mutta luulen, että se ei vieläkään riitä kehittämään intuitiota sen takana, mitä 0,75 AUC todellisuudessa tarkoittaa, katsokaamme nyt AUC-ROC:ta todennäköisyyden näkökulmasta. Puhutaan ensin siitä, mitä AUC tekee, ja myöhemmin rakennamme ymmärrystämme tämän päälle
AUC mittaa kuinka hyvin malli pystyy erottamaan toisistaan luokat.
AUC 0,75 tarkoittaisi itse asiassa sitä, että oletetaan kaksi eri luokkiin kuuluvaa datapistettä, jolloin on 75 %:n mahdollisuus, että malli pystyy erottamaan ne tai järjestämään ne oikein, eli positiivisella pisteellä on suurempi ennustetodennäköisyys kuin negatiivisella luokkaa. (suuremman ennustetodennäköisyyden olettaminen tarkoittaa, että piste kuuluisi ihanteellisesti positiiviseen luokkaan). Tässä pieni esimerkki asioiden selventämiseksi.
Indeksi | Luokka | Todennäköisyys |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Tässä meillä on 6 pistettä, joissa P1, P2 ja P5 kuuluvat luokkaan 1 ja P3, P4 ja P6 kuuluvat luokkaan 0 ja olemme vastaavia ennustettuja todennäköisyyksiä todennäköisyyssarakkeessa, kuten sanoimme, jos otamme kaksi pistettä, jotka kuuluvat erilliseen Millä todennäköisyydellä mallijärjestys järjestää ne oikein.
Otetaan kaikki mahdolliset parit siten, että yksi piste kuuluu luokkaan 1 ja toinen luokkaan 0, meillä on yhteensä 9 tällaista paria alla ovat kaikki nämä 9 mahdollista paria.
Pari | on oikein |
|---|---|
(P1, P3) | Joo |
(P1, P4) | Joo |
(P1, P6) | Joo |
(P2, P3) | Joo |
(P2, P4) | Joo |
(P2, P6) | Joo |
(P3, P5) | Ei |
(P4, P5) | Ei |
(P5, P6) | Joo |
Tässä sarake on Oikein kertoo, onko mainittu pari järjestetty oikein ennustetun todennäköisyyden perusteella eli luokan 1 pisteellä on suurempi todennäköisyys kuin luokan 0 pisteellä, näistä 9 mahdollisesta parista seitsemässä luokka 1 on luokkaa 0 korkeampi, tai voimme sanoa, että on 77% todennäköisyys, että jos valitset eri luokkiin kuuluvan pisteparin, malli pystyisi erottamaan ne oikein. Luulen, että sinulla saattaa olla hieman intuitiota tämän AUC-numeron takana. Epäilysten poistamiseksi tarkistetaan se käyttämällä Scikit oppii AUC-ROC-toteutusta.
Python 3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Lähtö:
AUC for our sample data is 0.778>
Milloin meidän tulisi käyttää AUC-ROC-arviointimetriikkaa?
Joillakin alueilla ROC-AUC ei ehkä ole ihanteellinen. Tapauksissa, joissa tietojoukko on erittäin epätasapainoinen, ROC-käyrä voi antaa liian optimistisen arvion mallin suorituskyvystä . Tämä optimismiharha johtuu siitä, että ROC-käyrän väärien positiivisten määrä (FPR) voi tulla hyvin pieneksi, kun todellisten negatiivisten määrä on suuri.
Kun katsot FPR-kaavaa,

tarkkailemme ,
- Negatiiviluokka on enemmistössä, FPR:n nimittäjää hallitsevat True Negatives, minkä vuoksi FPR muuttuu vähemmän herkäksi vähemmistöluokkaan (positiiviseen luokkaan) liittyvien ennusteiden muutoksille.
- ROC-käyrät voivat olla sopivia, kun väärien positiivisten ja väärien negatiivisten kustannukset ovat tasapainossa ja tietojoukko ei ole voimakkaasti epätasapainossa.
Siinä tapauksessa Tarkkuus-palautuskäyrät voidaan käyttää, jotka tarjoavat vaihtoehtoisen arviointimetriikan, joka sopii paremmin epätasapainoisille tietojoukoille, keskittyen luokittelijan suorituskykyyn suhteessa positiiviseen (vähemmistö) luokkaan.
Spekuloidaan mallin suorituskykyä
- Korkea AUC (lähellä 1) osoittaa erinomaista erottelukykyä. Tämä tarkoittaa, että malli erottaa tehokkaasti nämä kaksi luokkaa ja sen ennusteet ovat luotettavia.
- Matala AUC (lähellä 0) viittaa huonoon suorituskykyyn. Tässä tapauksessa malli kamppailee erottaakseen positiiviset ja negatiiviset luokat, ja sen ennusteet eivät välttämättä ole luotettavia.
- AUC noin 0,5 tarkoittaa, että malli pohjimmiltaan tekee satunnaisia arvauksia. Se ei näytä kykyä erottaa luokkia, mikä osoittaa, että malli ei opi tiedosta mitään merkityksellisiä malleja.
AUC-ROC-käyrän ymmärtäminen
ROC-käyrässä x-akseli edustaa tyypillisesti väärää positiivista määrää (FPR) ja y-akseli edustaa todellista positiivista nopeutta (TPR), joka tunnetaan myös nimellä herkkyys tai palautus. Joten korkeampi x-akselin arvo (oikealle päin) ROC-käyrällä osoittaa korkeampaa väärää positiivista suhdetta, ja korkeampi y-akselin arvo (yläosaa kohti) osoittaa korkeampaa True Positive Rate -arvoa. ROC-käyrä on graafinen esitys todellisen positiivisen määrän ja väärän positiivisen määrän välisestä kompromissista eri kynnyksillä. Se näyttää luokitusmallin suorituskyvyn eri luokituskynnyksillä. AUC (Area Under the Curve) on ROC-käyrän suorituskyvyn yhteenvetomitta. Kynnyksen valinta riippuu ratkaistavan ongelman erityisvaatimuksista ja väärien positiivisten ja väärien negatiivisten tulosten välisestä kompromissista. hyväksyttävää kontekstissasi.
- Jos haluat priorisoida väärien positiivisten tulosten vähentämisen (minimoiden mahdollisuudet merkitä jotain positiiviseksi, vaikka se ei ole), voit valita kynnyksen, joka johtaa pienempään väärien positiivisten määrään.
- Jos haluat priorisoida todellisten positiivisten osien lisäämisen (mahdollisimman monien todellisten positiivisten tallentamista), voit valita kynnyksen, joka johtaa korkeampaan todelliseen positiiviseen määrään.
Tarkastellaan esimerkkiä, joka havainnollistaa, kuinka ROC-käyrät luodaan erilaisille kynnysarvot ja kuinka tietty kynnysarvo vastaa sekaannusmatriisia. Oletetaan, että meillä on a binääriluokitusongelma mallilla, joka ennustaa, onko sähköposti roskapostia (positiivinen) vai ei roskapostia (negatiivinen).
Tarkastellaanpa hypoteettisia tietoja,
Todelliset tunnisteet: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Ennustetut todennäköisyydet: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Tapaus 1: Kynnys = 0,5
Oikeat etiketit | Ennustetut todennäköisyydet | Ennustetut etiketit |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 muuntaa char merkkijonoksi java | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Sekaannusmatriisi, joka perustuu yllä oleviin ennusteisiin
| Ennuste = 0 | Ennustus = 1 |
|---|---|---|
Todellinen = 0 | TP = 4 | FN=1 |
Todellinen = 1 | FP = 0 | TN = 5 |
Asianmukaisesti,
- Todellinen positiivinen korko (TPR) :
Luokittajan oikein tunnistamien todellisten positiivisten tulosten osuus on

- Väärin positiivinen määrä (FPR) :
Väärin positiivisiksi luokiteltujen todellisten negatiivisten osuus



Joten 0,5:n kynnyksellä:
- Todellinen positiivinen määrä (herkkyys): 0,8
- Väärin positiivinen arvo: 0
Tulkinta on, että malli tällä kynnysarvolla tunnistaa oikein 80 % todellisista positiivisista (TPR), mutta luokittelee 0 % todellisista negatiivisista väärin positiivisiksi (FPR).
Vastaavasti eri kynnyksillä saamme ,
Tapaus 2: Kynnys = 0,7
Oikeat etiketit | Ennustetut todennäköisyydet | Ennustetut etiketit |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 0 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Sekaannusmatriisi, joka perustuu yllä oleviin ennusteisiin
| Ennuste = 0 | Ennustus = 1 |
|---|---|---|
Todellinen = 0 | TP = 5 | FN = 0 |
Todellinen = 1 | FP = 2 | TN = 3 |
Asianmukaisesti,
- Todellinen positiivinen korko (TPR) :
Luokittajan oikein tunnistamien todellisten positiivisten tulosten osuus on

- Väärin positiivinen määrä (FPR) :
Väärin positiivisiksi luokiteltujen todellisten negatiivisten osuus



Tapaus 3: Kynnys = 0,4
Oikeat etiketit | Ennustetut todennäköisyydet | Ennustetut etiketit |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Sekaannusmatriisi, joka perustuu yllä oleviin ennusteisiin
| Ennuste = 0 | Ennustus = 1 |
|---|---|---|
Todellinen = 0 | TP = 4 | FN=1 |
Todellinen = 1 | FP = 0 | TN = 5 |
Asianmukaisesti,
- Todellinen positiivinen korko (TPR) :
Luokittajan oikein tunnistamien todellisten positiivisten tulosten osuus on
- Väärin positiivinen määrä (FPR) :
Väärin positiivisiksi luokiteltujen todellisten negatiivisten osuus
Tapaus 4: Kynnys = 0,2
Oikeat etiketit | Ennustetut todennäköisyydet | Ennustetut etiketit |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 1 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 1 |
| 0 | 0.1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Sekaannusmatriisi, joka perustuu yllä oleviin ennusteisiin
| Ennuste = 0 | Ennustus = 1 konekirjoitussarja |
|---|---|---|
Todellinen = 0 | TP = 2 | FN=3 |
Todellinen = 1 | FP = 0 | TN = 5 |
Asianmukaisesti,
- Todellinen positiivinen korko (TPR) :
Luokittajan oikein tunnistamien todellisten positiivisten tulosten osuus on

- Väärin positiivinen määrä (FPR) :
Väärin positiivisiksi luokiteltujen todellisten negatiivisten osuus

Tapaus 5: Kynnys = 0,85
Oikeat etiketit | Ennustetut todennäköisyydet | Ennustetut etiketit |
|---|---|---|
| 1 | 0.8 | 0 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 0 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Sekaannusmatriisi, joka perustuu yllä oleviin ennusteisiin
| Ennuste = 0 | Ennustus = 1 |
|---|---|---|
Todellinen = 0 | TP = 5 | FN = 0 |
Todellinen = 1 | FP = 4 | TN = 1 |
Asianmukaisesti,
- Todellinen positiivinen korko (TPR) :
Luokittajan oikein tunnistamien todellisten positiivisten tulosten osuus on
- Väärin positiivinen määrä (FPR) :
Väärin positiivisiksi luokiteltujen todellisten negatiivisten osuus


Yllä olevan tuloksen perusteella piirrämme ROC-käyrän
Python 3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Lähtö:
Kaaviosta käy ilmi, että:
- Harmaa katkoviiva edustaa pahinta skenaariota, jossa mallin ennusteet eli TPR ovat FPR ovat samat. Tätä vinoviivaa pidetään pahimpana tapauksena, mikä osoittaa yhtä suuren todennäköisyyden väärille positiivisille ja väärille negatiivisille.
- Kun pisteet poikkeavat satunnaisesta arvausviivasta kohti vasenta yläkulmaa, mallin suorituskyky paranee.
- Käyrän alla oleva pinta-ala (AUC) on kvantitatiivinen mitta mallin erottelukyvystä. Korkeampi AUC-arvo, lähempänä arvoa 1,0, osoittaa ylivoimaista suorituskykyä. Paras mahdollinen AUC-arvo on 1,0, mikä vastaa mallia, joka saavuttaa 100 % herkkyyden ja 100 % spesifisyyden.
Kaiken kaikkiaan ROC (Receiver Operating Characteristic) -käyrä toimii graafisena esitysnä binääriluokitusmallin todellisen positiivisen taajuuden (herkkyys) ja väärän positiivisen taajuuden välisestä kompromissista eri päätöskynnyksillä. Kun käyrä kohoaa sulavasti kohti vasenta yläkulmaa, se osoittaa mallin kiitettävää kykyä erottaa positiiviset ja negatiiviset tapaukset useilla luottamuskynnyksillä. Tämä ylöspäin suuntautuva liikerata osoittaa parempaa suorituskykyä, jolloin saavutetaan suurempi herkkyys ja minimoidaan vääriä positiivisia. Annotoidut kynnysarvot, joita merkitään A, B, C, D ja E, tarjoavat arvokasta tietoa mallin dynaamisesta käyttäytymisestä eri luottamustasoilla.
Toteutus kahdella eri mallilla
Kirjastojen asentaminen
Python 3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Kouluttaakseen Satunnainen metsä ja Logistinen regressio malleja ja esittääkseen niiden ROC-käyrät AUC-pisteillä, algoritmi luo keinotekoista binaarista luokitusdataa.
Datan luominen ja tietojen jakaminen
Python 3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Käyttämällä 80-20 jakosuhdetta, algoritmi luo keinotekoisen binääriluokitteludatan, jossa on 20 ominaisuutta, jakaa sen harjoitus- ja testausjoukkoon ja määrittää satunnaisen siemenen toistettavuuden varmistamiseksi.
Eri mallien koulutus
Python 3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Käyttämällä kiinteää satunnaista siementä toistettavuuden varmistamiseksi, menetelmä alustaa ja kouluttaa logistisen regressiomallin harjoitussarjaan. Samalla tavalla se käyttää harjoitustietoja ja samaa satunnaista siementä alustaakseen ja kouluttaakseen Random Forest -mallin, jossa on 100 puuta.
Ennusteet
Python 3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Käyttämällä testitietoja ja koulutettuja Logistinen regressio mallissa koodi ennustaa positiivisen luokan todennäköisyyden. Samalla tavalla se käyttää testidataa käyttämällä koulutettua Random Forest -mallia tuottamaan positiivisen luokan ennustetut todennäköisyydet.
Tietokehyksen luominen
Python 3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Testitietojen avulla koodi luo DataFrame-nimisen test_df-nimisen sarakkeilla True, Logistic ja RandomForest, lisää todellisia nimiä ja ennustettuja todennäköisyyksiä Random Forest- ja Logistic Regression -malleista.
Piirrä mallien ROC-käyrä
Python 3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Lähtö:

Koodi luo kaavion, jossa on 8 x 6 tuuman luvut. Se laskee AUC- ja ROC-käyrät kullekin mallille (Random Forest and Logistic Regression) ja piirtää sitten ROC-käyrän. The ROC-käyrä satunnaista arvausta edustaa myös punainen katkoviiva, ja tarrat, otsikko ja selite asetetaan visualisointia varten.
Kuinka käyttää ROC-AUC:ta moniluokkaisessa mallissa?
Usean luokan asetuksissa voimme yksinkertaisesti käyttää yksi vs kaikki -metodologiaa ja sinulla on yksi ROC-käyrä jokaiselle luokalle. Oletetaan, että sinulla on neljä luokkaa A, B, C ja D, jolloin kaikilla neljällä luokalla olisi ROC-käyrät ja vastaavat AUC-arvot, eli kun A olisi yksi luokka ja B, C ja D yhdistettynä muut luokka , samoin B on yksi luokka ja A, C ja D yhdistetty muihin luokkaan jne.
Yleiset vaiheet AUC-ROC:n käyttämiseksi moniluokkaisen luokitusmallin yhteydessä ovat:
Yksi vastaan kaikki -metodologia:
- Käsittele jokaista moniluokkaisen ongelmasi luokkaa positiivisena luokkana ja yhdistä kaikki muut luokat negatiiviseen luokkaan.
- Harjoittele kunkin luokan binääriluokittajaa muihin luokkiin verrattuna.
Laske AUC-ROC jokaiselle luokalle:
- Tässä piirretään tietyn luokan ROC-käyrä muihin verrattuna.
- Piirrä kunkin luokan ROC-käyrät samaan kuvaajaan. Jokainen käyrä edustaa mallin erottelukykyä tietyssä luokassa.
- Tarkista kunkin luokan AUC-pisteet. Korkeampi AUC-pistemäärä osoittaa parempaa erottelua kyseisessä luokassa.
AUC-ROC:n käyttöönotto moniluokkaluokituksessa
Kirjastojen tuonti
Python 3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Ohjelma luo keinotekoista moniluokkaista dataa, jakaa sen harjoitus- ja testaussarjoiksi ja käyttää sitten Yksi-vs-luokittelu tekniikkaa kouluttaa luokittelijat sekä Random Forest että Logistic Regression. Lopuksi se piirtää kahden mallin moniluokkaiset ROC-käyrät osoittamaan, kuinka hyvin ne erottelevat eri luokkia.
Datan luominen ja jakaminen
Python 3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Kolme luokkaa ja kaksikymmentä ominaisuutta muodostavat koodin tuottaman synteettisen moniluokkatiedon. Tarran binarisoinnin jälkeen tiedot jaetaan koulutus- ja testaussarjoihin suhteessa 80-20.
Koulutusmallit
Python 3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Ohjelma kouluttaa kaksi moniluokkaista mallia: Random Forest -mallin 100 estimaattorilla ja logistisen regressiomallin, jossa on Yksi vs-lepo -lähestymistapa . Harjoitteludatan avulla molemmat mallit on asennettu.
AUC-ROC-käyrän piirtäminen
Python 3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Lähtö:

Random Forest- ja Logistic Regression -mallien ROC-käyrät ja AUC-pisteet lasketaan kunkin luokan koodilla. Sitten piirretään moniluokkaiset ROC-käyrät, jotka osoittavat kunkin luokan erottelukyvyn ja viivalla, joka edustaa satunnaista arvausta. Tuloksena oleva juoni tarjoaa graafisen arvion mallien luokittelusuorituskyvystä.
Johtopäätös
Koneoppimisessa binääriluokittelumallien suorituskykyä arvioidaan käyttämällä ratkaisevaa metriikkaa, nimeltä Area Under the Receiver Operating Characteristic (AUC-ROC). Eri päätöskynnysten ylitse se osoittaa, kuinka herkkyys ja spesifisyys vaihdetaan. Suurempi ero positiivisten ja negatiivisten tapausten välillä on tyypillisesti esillä mallissa, jolla on korkeampi AUC-pistemäärä. Kun 0,5 tarkoittaa sattumaa, 1 tarkoittaa virheetöntä suorituskykyä. Mallin optimointia ja valintaa auttavat AUC-ROC-käyrän tarjoamat hyödylliset tiedot mallin kyvystä erottaa luokkia. Työskenneltäessä epätasapainoisten tietojoukkojen tai sovellusten kanssa, joissa väärien positiivisten ja väärien negatiivisten kustannukset ovat erilaiset, se on erityisen hyödyllinen kokonaisvaltaisena toimenpiteenä.
Usein kysyttyä AUC ROC -käyrästä koneoppimisessa
1. Mikä on AUC-ROC-käyrä?
Eri luokituskynnyksillä todellisen positiivisen määrän (herkkyys) ja väärän positiivisuuden (spesifisyys) välinen kompromissi esitetään graafisesti AUC-ROC-käyrällä.
2. Miltä täydellinen AUC-ROC-käyrä näyttää?
Alue 1 ihanteellisella AUC-ROC-käyrällä tarkoittaisi, että malli saavuttaa optimaalisen herkkyyden ja spesifisyyden kaikilla kynnyksillä.
3. Mitä AUC-arvo 0,5 tarkoittaa?
AUC 0,5 osoittaa, että mallin suorituskyky on verrattavissa satunnaisen sattuman suorituskykyyn. Se viittaa erottelukyvyn puutteeseen.
4. Voidaanko AUC-ROC:ia käyttää moniluokkaluokitukseen?
AUC-ROC:ta käytetään usein asioihin, joihin liittyy binääriluokitus. Muutokset, kuten makrokeskiarvo tai mikrokeskiarvo AUC voidaan ottaa huomioon moniluokkaluokituksessa.
5. Miten AUC-ROC-käyrästä on hyötyä mallin arvioinnissa?
Mallin kyky erottaa luokkia on kattavasti tiivistetty AUC-ROC-käyrällä. Se on erityisen hyödyllistä työskennellessäsi epätasapainoisten tietojoukkojen kanssa.