Logistinen regressio on valvottu koneoppimisalgoritmi käytetty luokittelutehtävät jossa tavoitteena on ennustaa todennäköisyys, että ilmentymä kuuluu tiettyyn luokkaan vai ei. Logistinen regressio on tilastollinen algoritmi, joka analysoi kahden datatekijän välistä suhdetta. Artikkelissa tarkastellaan logistisen regression perusteita, sen tyyppejä ja toteutuksia.
Sisällysluettelo
- Mikä on logistinen regressio?
- Logistinen toiminto – Sigmoid-toiminto
- Logistisen regression tyypit
- Logistisen regression oletukset
- Miten logistinen regressio toimii?
- Logistisen regression koodin käyttöönotto
- Tarkkuus-palautuksen kompromissi logistisen regression kynnysasetuksessa
- Kuinka arvioida logistinen regressiomalli?
- Erot lineaarisen ja logistisen regression välillä
Mikä on logistinen regressio?
Logistista regressiota käytetään binäärissä luokittelu missä käytämme sigmoiditoiminto , joka ottaa syötteen itsenäisinä muuttujina ja tuottaa todennäköisyysarvon välillä 0 ja 1.
Esimerkiksi meillä on kaksi luokkaa Luokka 0 ja luokka 1, jos syötteen logistisen funktion arvo on suurempi kuin 0,5 (kynnysarvo), niin se kuuluu luokkaan 1, muuten se kuuluu luokkaan 0. Sitä kutsutaan regressioksi, koska se on laajennus lineaarinen regressio mutta sitä käytetään pääasiassa luokitteluongelmiin.
Avainkohdat:
- Logistinen regressio ennustaa kategorisen riippuvan muuttujan tuoton. Siksi tuloksen on oltava kategorinen tai erillinen arvo.
- Se voi olla joko Kyllä tai Ei, 0 tai 1, tosi tai epätosi jne., mutta sen sijaan, että se antaisi tarkan arvon 0 ja 1, se antaa todennäköisyysarvot, jotka ovat välillä 0 ja 1.
- Logistisessa regressiossa sovitetaan regressioviivan sijaan S:n muotoinen logistinen funktio, joka ennustaa kaksi maksimiarvoa (0 tai 1).
Logistinen toiminto – Sigmoid-toiminto
- Sigmoidifunktio on matemaattinen funktio, jota käytetään kartoittaa ennustetut arvot todennäköisyyksiksi.
- Se kuvaa minkä tahansa todellisen arvon toiseksi arvoksi välillä 0 ja 1. Logistisen regression arvon tulee olla välillä 0 - 1, mikä ei voi ylittää tätä rajaa, joten se muodostaa S-muodon kaltaisen käyrän.
- S-muotoista käyrää kutsutaan sigmoidifunktioksi tai logistiseksi funktioksi.
- Logistisessa regressiossa käytämme kynnysarvon käsitettä, joka määrittelee joko 0:n tai 1:n todennäköisyyden. Esimerkiksi kynnysarvon ylittävät arvot pyrkivät 1:een ja kynnysarvojen alapuolella olevat arvot yleensä 0:aan.
Logistisen regression tyypit
Luokkien perusteella logistinen regressio voidaan jakaa kolmeen tyyppiin:
- Binomi: Binomiaalisessa logistisessa regressiossa voi olla vain kaksi mahdollista riippuvaisten muuttujien tyyppiä, kuten 0 tai 1, Hyväksytty tai Hylätty jne.
- Moninomi: Moninomisessa logistisessa regressiossa voi olla 3 tai useampia mahdollisia järjestämättömiä riippuvaisen muuttujan tyyppejä, kuten kissa, koira tai lammas
- Tavallinen: Ordinaalisessa logistisessa regressiossa voi olla 3 tai useampia mahdollisia järjestetyn tyyppisiä riippuvia muuttujia, kuten matala, keskitaso tai korkea.
Logistisen regression oletukset
Tutkimme logistisen regression oletuksia, koska näiden oletusten ymmärtäminen on tärkeää, jotta voimme varmistaa, että käytämme mallin asianmukaista sovellusta. Oletukseen sisältyy:
- Riippumattomat havainnot: Jokainen havainto on riippumaton toisistaan. mikä tarkoittaa, että minkään syöttömuuttujan välillä ei ole korrelaatiota.
- Binääririippuvaiset muuttujat: Oletetaan, että riippuvaisen muuttujan on oltava binäärinen tai kaksijakoinen, mikä tarkoittaa, että sillä voi olla vain kaksi arvoa. Useampaan kuin kahteen kategoriaan käytetään SoftMax-toimintoja.
- Riippumattomien muuttujien ja logaritmisten kertoimien välinen lineaarisuussuhde: Riippumattomien muuttujien ja riippuvan muuttujan logaritmisten välisen suhteen tulee olla lineaarinen.
- Ei poikkeavia: Tietojoukossa ei saa olla poikkeavuuksia.
- Suuri otoskoko: Otoskoko on riittävän suuri
Logistiseen regressioon liittyvät terminologiat
Tässä on joitain yleisiä termejä, jotka liittyvät logistiseen regressioon:
- Riippumattomat muuttujat: Syöttöominaisuudet tai ennustajatekijät, joita sovelletaan riippuvaisen muuttujan ennusteisiin.
- Riippuva muuttuja: Logistisen regressiomallin tavoitemuuttuja, jota yritämme ennustaa.
- Logistinen toiminto: Kaava, jota käytetään kuvaamaan, kuinka riippumattomat ja riippuvat muuttujat liittyvät toisiinsa. Logistinen funktio muuntaa syötemuuttujat todennäköisyysarvoiksi välillä 0 ja 1, mikä edustaa todennäköisyyttä, että riippuva muuttuja on 1 tai 0.
- Kertoimet: Se on jonkin tapahtuvan suhde johonkin, joka ei tapahdu. se eroaa todennäköisyydestä, koska todennäköisyys on jonkin tapahtuman suhde kaikkeen, mitä mahdollisesti voi tapahtua.
- Log-kertoimet: Log-odds, joka tunnetaan myös nimellä logit-funktio, on kertoimien luonnollinen logaritmi. Logistisessa regressiossa riippuvan muuttujan logaritmit mallinnetaan riippumattomien muuttujien ja leikkauspisteen lineaarisena yhdistelmänä.
- Kerroin: Logistisen regressiomallin estimoidut parametrit osoittavat, kuinka riippumattomat ja riippuvat muuttujat liittyvät toisiinsa.
- Siepata: Logistisen regressiomallin vakiotermi, joka edustaa logaritmistimiä, kun kaikki riippumattomat muuttujat ovat nolla.
- Maksimitodennäköisyysarvio : Logistisen regressiomallin kertoimien estimointiin käytetty menetelmä, joka maksimoi mallin antamien tietojen havainnoinnin todennäköisyyden.
Miten logistinen regressio toimii?
Logistinen regressiomalli muuttaa lineaarinen regressio funktio jatkuvan arvon ulostulo kategoriseksi arvoksi käyttämällä sigmoidifunktiota, joka kuvaa minkä tahansa syötetyn riippumattomien muuttujien reaaliarvoisen joukon arvoksi välillä 0 ja 1. Tämä funktio tunnetaan logistiikkafunktiona.
ohjelma javassa
Olkoon itsenäiset tuloominaisuudet:
ja riippuva muuttuja on Y, jolla on vain binääriarvo, eli 0 tai 1.
Käytä sitten monilineaarista funktiota syötemuuttujiin X.
Tässä
mistä keskustelimme edellä on lineaarinen regressio .
Sigmoiditoiminto
Nyt käytämme sigmoiditoiminto jossa syöte on z ja löydämme todennäköisyyden välillä 0 ja 1. eli ennustettu y.
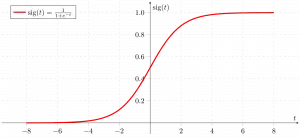
Sigmoid-toiminto
Kuten yllä on esitetty, kuvion sigmoidifunktio muuntaa jatkuvan muuttujan datan todennäköisyys eli välillä 0 ja 1.
sigma(z) suuntautuu kohti 1 asz ightarrowinfty sigma(z) suuntautuu kohti 0 asz ightarrow-infty sigma(z) on aina rajoittunut välillä 0 ja 1
jossa todennäköisyys olla luokka voidaan mitata seuraavasti:
Logistinen regressioyhtälö
Pariton on jonkin tapahtuman suhde johonkin, joka ei tapahdu. se eroaa todennäköisyydestä, koska todennäköisyys on jonkin tapahtuman suhde kaikkeen, mitä mahdollisesti voi tapahtua. niin outoa olisi:
Luonnollisen lokin käyttäminen parittomalla. sitten log odd on:
niin lopullinen logistinen regressioyhtälö on:
Logistisen regression todennäköisyysfunktio
Ennustetut todennäköisyydet ovat:
- jos y=1 Ennustetut todennäköisyydet ovat: p(X;b,w) = p(x)
- jos y = 0 Ennustetut todennäköisyydet ovat: 1-p(X;b,w) = 1-p(x)
Otetaan luonnonhirsiä molemmilta puolilta
smtp Internet-protokolla
Log-likelihood-funktion gradientti
Suurimman todennäköisyyden arvioiden löytämiseksi erottelemme w.r.t w,
Logistisen regression koodin käyttöönotto
Binomiaalinen logistinen regressio:
Kohdemuuttujalla voi olla vain 2 mahdollista tyyppiä: 0 tai 1, jotka voivat edustaa voitto vs tappio, hylätty vs epäonnistuminen, kuollut vs elossa jne., tässä tapauksessa käytetään sigmoidifunktioita, joista on jo keskusteltu edellä.
Tarvittavien kirjastojen tuonti mallivaatimuksen perusteella. Tämä Python-koodi näyttää, kuinka rintasyöpätietoaineistoa käytetään logistisen regressiomallin toteuttamiseen luokittelua varten.
Python 3 # import the necessary libraries from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # load the breast cancer dataset X, y = load_breast_cancer(return_X_y=True) # split the train and test dataset X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=23) # LogisticRegression clf = LogisticRegression(random_state=0) clf.fit(X_train, y_train) # Prediction y_pred = clf.predict(X_test) acc = accuracy_score(y_test, y_pred) print('Logistic Regression model accuracy (in %):', acc*100)> Lähtö :
Logistisen regressiomallin tarkkuus (%): 95,6140350877193
Multinomiaalinen logistinen regressio:
Kohdemuuttujalla voi olla 3 tai useampia mahdollisia tyyppejä, joita ei ole järjestetty (eli tyypeillä ei ole kvantitatiivista merkitystä), kuten sairaus A vs. tauti B vs. tauti C.
Tässä tapauksessa softmax-funktiota käytetään sigmoidifunktion sijasta. Softmax-toiminto K-luokille tulee:
Tässä, K edustaa elementtien lukumäärää vektorissa z, ja i, j iteroituu kaikkien vektorin elementtien yli.
Silloin luokan c todennäköisyys on:
Multinomial Logistic Regressionissa lähtömuuttujalla voi olla enemmän kuin kaksi mahdollista erillistä lähtöä . Harkitse numerotietojoukkoa.
Python 3 from sklearn.model_selection import train_test_split from sklearn import datasets, linear_model, metrics # load the digit dataset digits = datasets.load_digits() # defining feature matrix(X) and response vector(y) X = digits.data y = digits.target # splitting X and y into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1) # create logistic regression object reg = linear_model.LogisticRegression() # train the model using the training sets reg.fit(X_train, y_train) # making predictions on the testing set y_pred = reg.predict(X_test) # comparing actual response values (y_test) # with predicted response values (y_pred) print('Logistic Regression model accuracy(in %):', metrics.accuracy_score(y_test, y_pred)*100)> Lähtö:
Logistisen regressiomallin tarkkuus (%): 96,52294853963839
Kuinka arvioida logistinen regressiomalli?
Voimme arvioida logistisen regressiomallin seuraavilla mittareilla:
- Tarkkuus: Tarkkuus antaa oikein luokiteltujen tapausten osuuden.
Accuracy = frac{True , Positives + True , Negatives}{Total}
- Tarkkuus: Tarkkuus keskittyy positiivisten ennusteiden tarkkuuteen.
Precision = frac{True , Positives }{True, Positives + False , Positives}
- Muista (herkkyys tai todellinen positiivinen prosentti): Palauttaa mieleen mittaa oikein ennustettujen positiivisten tapausten osuutta kaikista todellisista positiivisista tapauksista.
Recall = frac{ True , Positives}{True, Positives + False , Negatives}
- F1-pisteet: F1-pisteet on tarkkuuden ja muistamisen harmoninen keskiarvo.
F1 , Score = 2 * frac{Precision * Recall}{Precision + Recall}
- Vastaanottimen toimintakäyrän alla oleva alue (AUC-ROC): ROC-käyrä kuvaa todellisen positiivisen määrän suhteessa vääriin positiivisiin prosenttiosuuksiin eri kynnyksillä. AUC-ROC mittaa tämän käyrän alla olevaa pinta-alaa ja tarjoaa kokonaismitan mallin suorituskyvystä eri luokituskynnysten yli.
- Tarkkuus-palautuskäyrän alla oleva alue (AUC-PR): Samanlainen kuin AUC-ROC, AUC-PR mittaa tarkkuus-palautuskäyrän alla olevaa aluetta ja tarjoaa yhteenvedon mallin suorituskyvystä eri tarkkuuden palauttamisen kompromisseissa.
Tarkkuus-palautuksen kompromissi logistisen regression kynnysasetuksessa
Logistisesta regressiosta tulee luokittelutekniikka vasta, kun päätöskynnys tuodaan kuvaan. Kynnysarvon asettaminen on erittäin tärkeä näkökohta logistisessa regressiossa ja riippuu itse luokitteluongelmasta.
Kynnysarvon arvopäätökseen vaikuttavat suuresti arvot tarkkuutta ja muistamista. Ihannetapauksessa haluamme sekä tarkkuuden että muistamisen olevan 1, mutta näin on harvoin.
Tapauksessa a Precision-Recall kompromissi , käytämme seuraavia argumentteja kynnyksen määrittämiseen:
- Matala tarkkuus / korkea palautus: Sovelluksissa, joissa haluamme vähentää väärien negatiivien määrää vähentämättä välttämättä väärien positiivisten määrää, valitsemme päätösarvon, jolla on pieni Tarkkuus- tai korkea Recall-arvo. Esimerkiksi syöpädiagnoosisovelluksessa emme halua, että yksikään sairastunut potilas luokitellaan sairaamattomaksi ottamatta huomioon, jos potilaalla on virheellisesti diagnosoitu syöpä. Tämä johtuu siitä, että syövän puuttuminen voidaan havaita muilla lääketieteellisillä sairauksilla, mutta taudin esiintymistä ei voida havaita jo hylätyssä ehdokkaassa.
- Suuri tarkkuus / alhainen palautus: Sovelluksissa, joissa haluamme vähentää väärien positiivisten määrää vähentämättä välttämättä väärien negatiivien määrää, valitsemme päätösarvon, jolla on korkea Precision-arvo tai alhainen Recall-arvo. Jos esimerkiksi luokittelemme asiakkaita, reagoivatko he positiivisesti vai negatiivisesti personoituun mainokseen, haluamme olla täysin varmoja, että asiakas reagoi mainokseen positiivisesti, koska muuten negatiivinen reaktio voi aiheuttaa potentiaalisen myynnin menetystä asiakas.
Erot lineaarisen ja logistisen regression välillä
Ero lineaarisen regression ja logistisen regression välillä on se, että lineaarisen regression tulos on jatkuva arvo, joka voi olla mikä tahansa, kun taas logistinen regressio ennustaa todennäköisyyden, kuuluuko esiintymä tiettyyn luokkaan vai ei.
Lineaarinen regressio | Logistinen regressio |
|---|---|
Lineaarista regressiota käytetään jatkuvan riippuvan muuttujan ennustamiseen käyttämällä annettua riippumattomien muuttujien joukkoa. | Logistista regressiota käytetään kategorisen riippuvan muuttujan ennustamiseen käyttämällä annettua riippumattomien muuttujien joukkoa. |
Lineaarista regressiota käytetään regressioongelman ratkaisemiseen. | Sitä käytetään luokitteluongelmien ratkaisemiseen. |
Tässä ennustamme jatkuvien muuttujien arvon | Tässä ennustamme kategoristen muuttujien arvoja |
Tästä löydämme parhaiten sopivan linjan. | Tästä löydämme S-käyrän. |
Tarkkuuden estimointiin käytetään pienimmän neliön estimointimenetelmää. | Maksimitodennäköisyyden estimointimenetelmää käytetään tarkkuuden estimointiin. |
Tuotoksen on oltava jatkuva arvo, kuten hinta, ikä jne. | Tulosteen on oltava kategorinen arvo, kuten 0 tai 1, Kyllä tai ei jne. |
Se vaati lineaarisen suhteen riippuvien ja riippumattomien muuttujien välillä. | Se ei vaadi lineaarista suhdetta. |
Riippumattomien muuttujien välillä voi olla kollineaarisuutta. | Riippumattomien muuttujien välillä ei pitäisi olla kollineaarisuutta. |
Logistinen regressio – Usein kysytyt kysymykset (FAQ)
Mitä on logistinen regressio koneoppimisessa?
Logistinen regressio on tilastollinen menetelmä kehittää koneoppimismalleja, joissa on binääririippuvaisia muuttujia, eli binäärisiä. Logistinen regressio on tilastollinen tekniikka, jota käytetään kuvaamaan tietoja ja yhden riippuvan muuttujan ja yhden tai useamman riippumattoman muuttujan välistä suhdetta.
Mitkä ovat kolme logistisen regression tyyppiä?
Logistinen regressio luokitellaan kolmeen tyyppiin: binääri, multinomi ja järjestysluku. Ne eroavat sekä toteutuksen että teorian osalta. Binääriregressiolla on kaksi mahdollista lopputulosta: kyllä tai ei. Multinomiaalista logistista regressiota käytetään, kun arvoja on kolme tai useampia.
arraylist
Miksi luokitusongelmassa käytetään logistista regressiota?
Logistinen regressio on helpompi toteuttaa, tulkita ja kouluttaa. Se luokittelee tuntemattomat tietueet hyvin nopeasti. Kun tietojoukko on lineaarisesti erotettavissa, se toimii hyvin. Mallin kertoimet voidaan tulkita ominaisuuden tärkeyden indikaattoreiksi.
Mikä erottaa logistisen regression lineaarisesta regressiosta?
Lineaarista regressiota käytetään ennustamaan jatkuvia tuloksia, kun taas logistista regressiota käytetään ennustamaan todennäköisyyttä, että havainto kuuluu tiettyyn luokkaan. Logistic Regression käyttää S-muotoista logistista funktiota kartoittamaan ennustetut arvot välillä 0 ja 1.
Mikä rooli logistiikkatoiminnolla on logistisessa regressiossa?
Logistinen regressio perustuu logistiseen funktioon, joka muuntaa tuotoksen todennäköisyyspisteiksi. Tämä pistemäärä edustaa todennäköisyyttä, että havainto kuuluu tiettyyn luokkaan. S-muotoinen käyrä auttaa tietojen kynnysmäärittelyssä ja luokittelussa binäärituloksiin.