Koneoppiminen on ala Tekoäly joka keskittyy sellaisten mallien ja algoritmien kehittämiseen, joiden avulla tietokoneet voivat oppia tiedoista ja kehittyä aiemman kokemuksen perusteella ilman, että niitä on erikseen ohjelmoitu jokaiseen tehtävään. Yksinkertaisesti sanottuna ML opettaa järjestelmiä ajattelemaan ja ymmärtämään ihmisten tavoin oppimalla tiedoista.
Tässä artikkelissa tutkimme erilaisia tyyppisiä koneoppimisalgoritmeja jotka ovat tärkeitä tulevien tarpeiden kannalta. Koneoppiminen on yleensä koulutusjärjestelmä, jossa opitaan aiemmista kokemuksista ja parannetaan suorituskykyä ajan myötä. Koneoppiminen auttaa ennustamaan valtavia tietomääriä. Se auttaa toimittamaan nopeita ja tarkkoja tuloksia kannattavien mahdollisuuksien saamiseksi.
Koneoppimisen tyypit
Koneoppimista on useita tyyppejä, joista jokaisella on erityispiirteitä ja -sovelluksia. Jotkut koneoppimisalgoritmien päätyypeistä ovat seuraavat:
- Valvottu koneoppiminen
- Valvomaton koneoppiminen
- Puoliohjattu koneoppiminen
- Vahvistusoppiminen
Koneoppimisen tyypit
merkkijono kokonaisluvuksi muuntaa
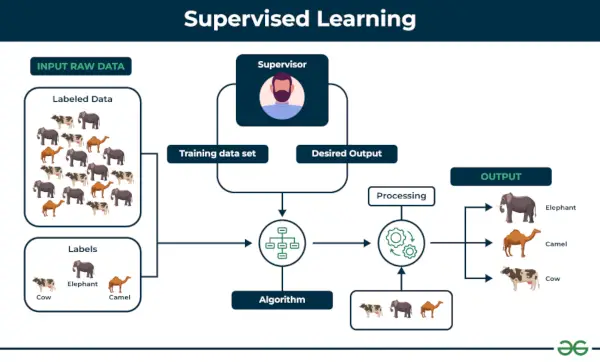
1. Valvottu koneoppiminen
Ohjattu oppiminen määritellään silloin, kun mallia koulutetaan a Merkitty tietojoukko . Merkityillä tietojoukoilla on sekä tulo- että lähtöparametrit. Sisään Ohjattu oppiminen Algoritmit oppivat kartoittamaan pisteitä tulojen ja oikeiden tulosten välillä. Siinä on sekä koulutus- että validointitietojoukot merkittyinä.
Ohjattu oppiminen
Ymmärretään se esimerkin avulla.
Esimerkki: Harkitse skenaariota, jossa sinun on rakennettava kuvan luokitin kissojen ja koirien erottamiseksi. Jos syötät algoritmiin koirien ja kissojen merkittyjen kuvien tietojoukot, kone oppii luokittelemaan koiran ja kissan näiden merkittyjen kuvien perusteella. Kun syötämme uusia koira- tai kissakuvia, joita se ei ole koskaan ennen nähnyt, se käyttää opittuja algoritmeja ja ennustaa, onko kyseessä koira vai kissa. Näin ohjattua oppimista toimii, ja tämä on erityisesti kuvaluokitus.
Ohjattua oppimista on kaksi pääluokkaa, jotka mainitaan alla:
- Luokittelu
- Regressio
Luokittelu
Luokittelu käsittelee ennustamista kategorinen kohdemuuttujat, jotka edustavat erillisiä luokkia tai tunnisteita. Esimerkiksi sähköpostien luokitteleminen roskapostiksi tai ei roskapostiksi tai sen ennustaminen, onko potilaalla suuri sydänsairauksien riski. Luokittelualgoritmit oppivat yhdistämään syöttöominaisuudet johonkin ennalta määritellyistä luokista.
Tässä on joitain luokittelualgoritmeja:
- Logistinen regressio
- Tuki Vector Machine
- Satunnainen metsä
- Päätöspuu
- K-Lähimmät naapurit (KNN)
- Naiivi Bayes
Regressio
Regressio , toisaalta, käsittelee ennustamista jatkuva kohdemuuttujat, jotka edustavat numeerisia arvoja. Esimerkiksi talon hinnan ennustaminen sen koon, sijainnin ja mukavuuksien perusteella tai tuotteen myynnin ennustaminen. Regressioalgoritmit oppivat yhdistämään syöteominaisuudet jatkuvaan numeeriseen arvoon.
Tässä on joitain regressioalgoritmeja:
- Lineaarinen regressio
- Polynomiregressio
- Ridge Regressio
- Lasson regressio
- Päätöspuu
- Satunnainen metsä
Valvotun koneoppimisen edut
- Ohjattu oppiminen mallit voivat olla erittäin tarkkoja, kun niitä on koulutettu merkittyjä tietoja .
- Päätöksentekoprosessi ohjatuissa oppimismalleissa on usein tulkittavissa.
- Sitä voidaan usein käyttää esikoulutetuissa malleissa, mikä säästää aikaa ja resursseja kehitettäessä uusia malleja tyhjästä.
Valvotun koneoppimisen haitat
- Sillä on rajoituksia kuvioiden tuntemisessa, ja se voi kamppailla näkymättömien tai odottamattomien kuvioiden kanssa, joita ei ole koulutustiedoissa.
- Se voi olla aikaa vievää ja kallista, koska se perustuu merkitty vain dataa.
- Se voi johtaa huonoihin yleistyksiin uuden tiedon perusteella.
Ohjatun oppimisen sovellukset
Ohjattua oppimista käytetään monenlaisissa sovelluksissa, mukaan lukien:
- Kuvan luokittelu : Tunnista kohteet, kasvot ja muut piirteet kuvista.
- Luonnollisen kielen käsittely: Poimi tekstistä tietoa, kuten tunteita, kokonaisuuksia ja suhteita.
- Puheentunnistus : Muunna puhuttu kieli tekstiksi.
- Suositusjärjestelmät : Anna käyttäjille henkilökohtaisia suosituksia.
- Ennakoiva analytiikka : Ennusta tuloksia, kuten myyntiä, asiakkaiden vaihtuvuutta ja osakekursseja.
- Lääketieteellinen diagnoosi : Tunnista sairaudet ja muut sairaudet.
- Petosten havaitseminen : Tunnista vilpilliset tapahtumat.
- Autonomiset ajoneuvot : Tunnista ympäristössä olevat esineet ja reagoi niihin.
- Sähköpostin roskapostin tunnistus : Luokittele sähköpostit roskapostiksi vai ei roskapostiksi.
- Laadunvalvonta valmistuksessa : Tarkista tuotteissa vikoja.
- Luottopisteytys : Arvioi riskiä siitä, että lainanottaja laiminlyö lainan.
- Pelaaminen : Tunnista hahmot, analysoi pelaajien käyttäytymistä ja luo NPC:itä.
- Asiakaspalvelu : Automatisoi asiakastukitehtävät.
- Sääennustus : Tee ennusteita lämpötilasta, sateesta ja muista sääparametreista.
- Urheiluanalytiikka : Analysoi pelaajien suorituskykyä, tee peliennusteita ja optimoi strategioita.
2. Valvomaton koneoppiminen
Ohjaamaton oppiminen Valvomaton oppiminen on eräänlainen koneoppimistekniikka, jossa algoritmi löytää kuvioita ja suhteita merkitsemättömän datan avulla. Toisin kuin ohjattu oppiminen, ohjaamaton oppiminen ei sisällä algoritmin tarjoamista merkittyjen kohdetulosteiden kanssa. Valvomattoman oppimisen ensisijainen tavoite on usein löytää piilotettuja malleja, yhtäläisyyksiä tai klustereita tiedoista, joita voidaan sitten käyttää eri tarkoituksiin, kuten tietojen tutkimiseen, visualisointiin, ulottuvuuksien vähentämiseen ja muihin tarkoituksiin.
lataa youtube vlc:llä
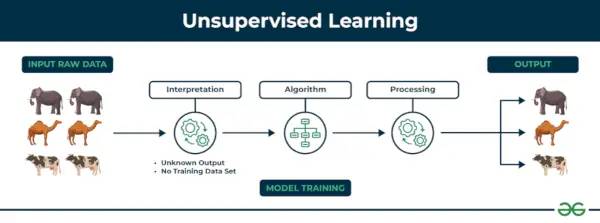
Ohjaamaton oppiminen
Ymmärretään se esimerkin avulla.
Esimerkki: Harkitse, että sinulla on tietojoukko, joka sisältää tietoja kaupasta tekemistäsi ostoksista. Klusteroinnin avulla algoritmi voi ryhmitellä saman ostokäyttäytymisen sinun ja muiden asiakkaiden kesken, mikä paljastaa potentiaaliset asiakkaat ilman ennalta määritettyjä tunnisteita. Tämän tyyppiset tiedot voivat auttaa yrityksiä saamaan kohdeasiakkaita sekä tunnistamaan poikkeamat.
Ohjaamattomassa oppimisessa on kaksi pääluokkaa, jotka mainitaan alla:
- Klusterointi
- yhdistys
Klusterointi
Klusterointi on prosessi, jossa datapisteet ryhmitellään klustereihin niiden samankaltaisuuden perusteella. Tämä tekniikka on hyödyllinen tietojen mallien ja suhteiden tunnistamiseen ilman merkittyjä esimerkkejä.
Tässä on joitain klusterointialgoritmeja:
- K-Means-klusterointialgoritmi
- Keskiarvon siirtymäalgoritmi
- DBSCAN-algoritmi
- Pääkomponenttianalyysi
- Itsenäinen komponenttianalyysi
yhdistys
Opi yhdistyssääntö ing on tekniikka tietojoukon kohteiden välisten suhteiden löytämiseksi. Se identifioi säännöt, jotka osoittavat, että yhden kohteen läsnäolo tarkoittaa toisen kohteen läsnäoloa tietyllä todennäköisyydellä.
Tässä on joitain assosiaatiosäännön oppimisalgoritmeja:
- Apriori algoritmi
- Hehku
- FP-kasvualgoritmi
Valvomattoman koneoppimisen edut
- Se auttaa löytämään piilotetut kuviot ja erilaiset suhteet tietojen välillä.
- Käytetään tehtäviin, kuten asiakkaiden segmentointi, poikkeamien havaitseminen, ja tietojen etsintä .
- Se ei vaadi merkittyjä tietoja ja vähentää tietojen merkitsemisen vaivaa.
Valvomattoman koneoppimisen haitat
- Ilman tarroja voi olla vaikea ennustaa mallin tulosteen laatua.
- Klusterin tulkinta ei välttämättä ole selkeää eikä sillä välttämättä ole merkityksellisiä tulkintoja.
- Siinä on tekniikoita mm automaattiset kooderit ja ulottuvuuden vähentäminen joita voidaan käyttää merkityksellisten ominaisuuksien poimimiseen raakatiedoista.
Ohjaamattoman oppimisen sovellukset
Tässä on joitain yleisiä ohjaamattoman oppimisen sovelluksia:
- Klusterointi : Ryhmittele samanlaiset datapisteet klustereihin.
- Anomalian havaitseminen : Tunnista poikkeamat tai poikkeamat tiedoista.
- Mittasuhteiden vähentäminen : Vähennä tietojen ulottuvuutta säilyttäen samalla sen olennaiset tiedot.
- Suositusjärjestelmät : Ehdota käyttäjille tuotteita, elokuvia tai sisältöä heidän historiallisen käyttäytymisensä tai mieltymyksiensä perusteella.
- Aihemallinnus : Löydä piileviä aiheita asiakirjojen kokoelmasta.
- Tiheyden arvio : Arvioi tietojen todennäköisyystiheysfunktio.
- Kuvan ja videon pakkaus : Vähennä multimediasisällölle tarvittavan tallennustilan määrää.
- Tietojen esikäsittely : Apua tietojen esikäsittelytehtävissä, kuten tietojen puhdistamisessa, puuttuvien arvojen imputoinnissa ja tietojen skaalauksessa.
- Markkinakori-analyysi : Tutustu tuotteiden välisiin assosiaatioihin.
- Genomitietojen analyysi : Tunnista kuviot tai ryhmittele geenit, joilla on samanlaiset ilmentymisprofiilit.
- Kuvan segmentointi : Segmentoi kuvat merkityksellisiksi alueiksi.
- Yhteisön havaitseminen sosiaalisissa verkostoissa : Tunnista yhteisöt tai yksilöryhmät, joilla on samanlaisia kiinnostuksen kohteita tai yhteyksiä.
- Asiakkaiden käyttäytymisen analyysi : Löydä malleja ja oivalluksia paremman markkinoinnin ja tuotesuositusten saamiseksi.
- Sisällön suositus : Luokittele ja merkitse sisältö, jotta samankaltaisten kohteiden suositteleminen käyttäjille on helpompaa.
- Tutkiva data-analyysi (EDA) : Tutki tietoja ja hanki oivalluksia ennen tiettyjen tehtävien määrittämistä.
3. Puoliohjattu oppiminen
Puoliohjattu oppiminen on koneoppimisalgoritmi, joka toimii välillä valvottu ja valvomaton oppimista, joten se käyttää molempia merkitty ja merkitsemätön tiedot. Se on erityisen hyödyllinen, kun merkittyjen tietojen hankkiminen on kallista, aikaa vievää tai resursseja. Tämä lähestymistapa on hyödyllinen, kun tietojoukko on kallis ja aikaa vievä. Puoliohjattu oppiminen valitaan, kun merkitty data vaatii taitoja ja asiaankuuluvia resursseja kouluttaakseen tai oppiakseen siitä.
Käytämme näitä tekniikoita, kun käsittelemme dataa, joka on hieman merkitty ja suuri osa siitä on nimeämätöntä. Voimme käyttää valvomattomia tekniikoita tarrojen ennustamiseen ja sitten syöttää nämä tarrat valvotuille tekniikoille. Tämä tekniikka on enimmäkseen sovellettavissa kuvatietosarjoihin, joissa yleensä kaikkia kuvia ei ole merkitty.
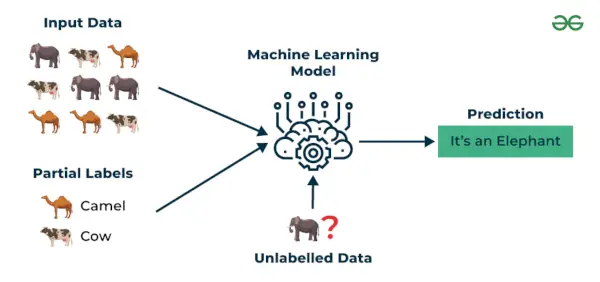
Puoliohjattu oppiminen
Ymmärretään se esimerkin avulla.
paikallinen päivämäärä
Esimerkki : Ajattele, että rakennamme kielikäännösmallia. Jokaisen lauseparin käännösten merkitseminen voi olla resurssiintensiivistä. Sen avulla mallit voivat oppia merkityistä ja merkitsemättömistä lausepareista, mikä tekee niistä tarkempia. Tämä tekniikka on johtanut huomattaviin parannuksiin konekäännöspalvelujen laadussa.
Puoliohjattujen oppimismenetelmien tyypit
On olemassa useita erilaisia puoliohjattuja oppimismenetelmiä, joilla jokaisella on omat ominaisuutensa. Jotkut yleisimmistä ovat:
- Graafipohjainen puoliohjattu oppiminen: Tämä lähestymistapa käyttää kuvaajaa kuvaamaan datapisteiden välisiä suhteita. Kuvaajaa käytetään sitten levittämään tunnisteita nimetyistä tietopisteistä merkitsemättömiin tietopisteisiin.
- Etiketin leviäminen: Tämä lähestymistapa siirtää tunnisteet iteratiivisesti merkityistä tietopisteistä merkitsemättömiin tietopisteisiin datapisteiden välisten yhtäläisyuksien perusteella.
- Yhteiskoulutus: Tämä lähestymistapa kouluttaa kahta erilaista koneoppimismallia merkitsemättömän datan eri osajoukoille. Näitä kahta mallia käytetään sitten merkitsemään toistensa ennusteita.
- Itseharjoittelu: Tämä lähestymistapa kouluttaa koneoppimismallin merkityille tiedoille ja käyttää sitten mallia ennustamaan tunnisteet merkitsemättömälle datalle. Malli opetetaan sitten uudelleen merkityille tiedoille ja ennustetuille leimaamattomille tiedoille.
- Generatiiviset vastavuoroiset verkot (GAN) : GAN:t ovat eräänlainen syväoppimisalgoritmi, jota voidaan käyttää synteettisen tiedon luomiseen. GAN-verkkoja voidaan käyttää luomaan leimaamatonta dataa puolivalvottua oppimista varten kouluttamalla kaksi hermoverkkoa, generaattorin ja erottimen.
Puoliohjatun koneoppimisen edut
- Se johtaa parempaan yleistykseen verrattuna ohjattua oppimista, koska se ottaa sekä merkittyjä että merkitsemättömiä tietoja.
- Voidaan soveltaa monenlaisiin tietoihin.
Puolivalvotun koneoppimisen haitat
- Puolivalvottu menetelmät voivat olla monimutkaisempia toteuttaa kuin muut lähestymistavat.
- Se vaatii silti jonkin verran merkittyjä tietoja joita ei välttämättä aina ole saatavilla tai helppo saada.
- Merkitsemättömät tiedot voivat vaikuttaa mallin suorituskykyyn vastaavasti.
Puoliohjatun oppimisen sovellukset
Tässä on joitain yleisiä puoliohjatun oppimisen sovelluksia:
- Kuvien luokittelu ja objektien tunnistus : Paranna mallien tarkkuutta yhdistämällä pieni joukko merkittyjä kuvia suurempaan joukkoon merkitsemättömiä kuvia.
- Natural Language Processing (NLP) : Paranna kielimallien ja luokittimien suorituskykyä yhdistämällä pieni joukko merkittyjä tekstitietoja suureen määrään merkitsemätöntä tekstiä.
- Puheentunnistus: Paranna puheentunnistuksen tarkkuutta hyödyntämällä rajoitettua määrää transkriboitua puhedataa ja laajempaa määrää merkitsemätöntä ääntä.
- Suositusjärjestelmät : Paranna räätälöityjen suositusten tarkkuutta täydentämällä harvaa käyttäjien ja kohteiden välisiä vuorovaikutuksia (merkitty data) runsaalla nimeämättömällä käyttäjien käyttäytymisdatalla.
- Terveydenhuolto ja lääketieteellinen kuvantaminen : Paranna lääketieteellisten kuvien analysointia käyttämällä pientä joukkoa merkittyjä lääketieteellisiä kuvia suuremman joukon merkitsemättömiä kuvia rinnalla.
4. Vahvistuskoneoppiminen
Vahvista koneoppimista Algoritmi on oppimismenetelmä, joka on vuorovaikutuksessa ympäristön kanssa tuottamalla toimintoja ja havaitsemalla virheitä. Kokeilu, virhe ja viive ovat vahvistusoppimisen tärkeimmät ominaisuudet. Tässä tekniikassa malli jatkaa suorituskyvyn parantamista käyttämällä palkkiopalautetta oppiakseen käyttäytymisen tai mallin. Nämä algoritmit ovat erityisiä tietylle ongelmalle, esim. Google Self Driving car, AlphaGo, jossa robotti kilpailee ihmisten ja jopa itsensä kanssa saadakseen yhä parempia suorituksia Go Gamessa. Joka kerta kun syötämme tietoja, he oppivat ja lisäävät tiedot tietoihinsa, jotka ovat koulutustietoja. Joten mitä enemmän se oppii, sitä paremmin se on koulutettu ja kokenut.
Tässä on joitain yleisimpiä vahvistusoppimisalgoritmeja:
- Q-oppiminen: Q-learning on malliton RL-algoritmi, joka oppii Q-funktion, joka kartoittaa tilat toimiin. Q-funktio arvioi odotetun palkkion tietyn toiminnon suorittamisesta tietyssä tilassa.
- SARSA (State-Action-Reward-State-Action): SARSA on toinen malliton RL-algoritmi, joka oppii Q-funktion. Toisin kuin Q-learning, SARSA kuitenkin päivittää Q-funktion todellisen suoritetun toiminnon mukaan optimaalisen toiminnon sijaan.
- Syvä Q-oppiminen : Deep Q-learning on yhdistelmä Q-oppimista ja syväoppimista. Deep Q-learning käyttää hermoverkkoa edustamaan Q-funktiota, jonka avulla se voi oppia monimutkaisia suhteita tilojen ja toimien välillä.
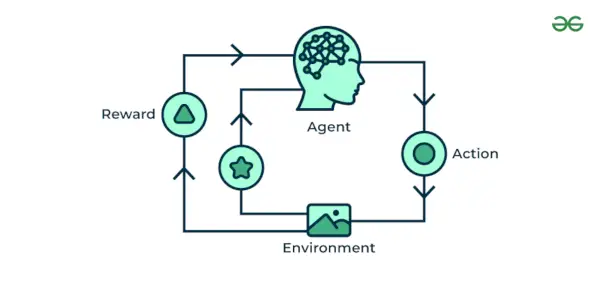
Vahvistuskoneoppiminen
Ymmärretään se esimerkkien avulla.
Esimerkki: Mieti, että harjoittelet AI agentti pelaamaan shakin kaltaista peliä. Agentti tutkii erilaisia liikkeitä ja saa tuloksen perusteella positiivista tai negatiivista palautetta. Vahvistusoppiminen löytää myös sovelluksia, joissa he oppivat suorittamaan tehtäviä vuorovaikutuksessa ympäristönsä kanssa.
Vahvistuskoneoppimisen tyypit
Vahvistusoppimista on kahta päätyyppiä:
Positiivinen vahvistus
- Palkitsee agenttia halutun toimenpiteen suorittamisesta.
- Kannustaa agenttia toistamaan käyttäytymistä.
- Esimerkkejä: herkuttelu koiralle istumisesta, pisteen antaminen pelissä oikeasta vastauksesta.
Negatiivinen vahvistus
- Poistaa ei-toivotun ärsykkeen kannustaakseen haluttuun käyttäytymiseen.
- Estää agenttia toistamasta käyttäytymistä.
- Esimerkkejä: Voimakkaan summerin sammuttaminen, kun vipua painetaan, rangaistuksen välttäminen suorittamalla tehtävä.
Vahvistuskoneoppimisen edut
- Siinä on autonominen päätöksenteko, joka sopii hyvin tehtäviin ja joka voi oppia tekemään sarjan päätöksiä, kuten robotiikkaa ja pelaamista.
- Tämä tekniikka on parempi saavuttaa pitkäaikaisia tuloksia, joita on erittäin vaikea saavuttaa.
- Sitä käytetään ratkaisemaan monimutkaisia ongelmia, joita ei voida ratkaista perinteisillä tekniikoilla.
Vahvistuskoneoppimisen haitat
- Koulutuksen vahvistaminen Oppimisagentit voivat olla laskennallisesti kalliita ja aikaa vieviä.
- Vahvistusoppiminen ei ole parempi kuin yksinkertaisten ongelmien ratkaiseminen.
- Se vaatii paljon dataa ja paljon laskentaa, mikä tekee siitä epäkäytännöllistä ja kallista.
Vahvistuskoneoppimisen sovellukset
Tässä on joitain vahvistusoppimisen sovelluksia:
- Pelin pelaaminen : RL voi opettaa agentteja pelaamaan pelejä, jopa monimutkaisia.
- Robotiikka : RL voi opettaa robotteja suorittamaan tehtäviä itsenäisesti.
- Autonomiset ajoneuvot : RL voi auttaa itseohjautuvia autoja navigoimaan ja tekemään päätöksiä.
- Suositusjärjestelmät : RL voi parantaa suositusalgoritmeja oppimalla käyttäjien mieltymyksiä.
- Terveydenhuolto : RL:ää voidaan käyttää hoitosuunnitelmien ja lääkekehityksen optimointiin.
- Natural Language Processing (NLP) : RL:ää voidaan käyttää dialogijärjestelmissä ja chatboteissa.
- Rahoitus ja kauppa : RL:tä voidaan käyttää algoritmiseen kaupankäyntiin.
- Toimitusketjun ja varastonhallinta : RL:ää voidaan käyttää toimitusketjun toimintojen optimointiin.
- Energian hallinta : RL:ää voidaan käyttää energiankulutuksen optimointiin.
- AI pelit : RL:n avulla voidaan luoda älykkäämpiä ja mukautuvampia NPC:itä videopeleihin.
- Mukautuvat henkilökohtaiset avustajat : RL:ää voidaan käyttää henkilökohtaisten avustajien parantamiseen.
- Virtuaalitodellisuus (VR) ja lisätty todellisuus (AR): RL:n avulla voidaan luoda mukaansatempaavia ja interaktiivisia kokemuksia.
- Teollinen ohjaus : RL:ää voidaan käyttää teollisten prosessien optimointiin.
- koulutus : RL:ää voidaan käyttää mukautuvien oppimisjärjestelmien luomiseen.
- Maatalous : RL:ää voidaan käyttää maataloustoiminnan optimointiin.
Täytyy tarkistaa, yksityiskohtainen artikkelimme : Koneoppimisalgoritmit
Johtopäätös
Yhteenvetona voidaan todeta, että jokainen koneoppimisen tyyppi palvelee omaa tarkoitustaan ja edistää yleistä roolia parannettujen datan ennustusominaisuuksien kehittämisessä, ja sillä on potentiaalia muuttaa eri toimialoja, kuten Tietotiede . Se auttaa käsittelemään massiivista tiedontuotantoa ja tietojoukkojen hallintaa.
Koneoppimisen tyypit – UKK
1. Mitä haasteita ohjatussa oppimisessa kohtaa?
Joitakin ohjatun oppimisen haasteita ovat pääasiassa luokkaepätasapainon korjaaminen, korkealaatuiset leimatut tiedot ja ylisovittamisen välttäminen, kun mallit toimivat huonosti reaaliaikaisten tietojen kanssa.
mini työkalupalkki excel
2. Missä voimme soveltaa ohjattua oppimista?
Ohjattua oppimista käytetään yleisesti tehtäviin, kuten roskapostien analysointiin, kuvien tunnistamiseen ja tunteiden analysointiin.
3. Miltä koneoppimisen tulevaisuus näyttää?
Koneoppiminen tulevaisuudennäkyminä voi toimia esimerkiksi sää- tai ilmastoanalyysissä, terveydenhuoltojärjestelmissä ja autonomisessa mallintamisessa.
4. Mitkä ovat koneoppimisen eri tyypit?
Koneoppimista on kolme päätyyppiä:
- Ohjattu oppiminen
- Ohjaamaton oppiminen
- Vahvistusoppiminen
5. Mitkä ovat yleisimmät koneoppimisalgoritmit?
Jotkut yleisimmistä koneoppimisalgoritmeista ovat:
- Lineaarinen regressio
- Logistinen regressio
- Tuki vektorikoneita (SVM)
- K-lähimmät naapurit (KNN)
- Päätöspuut
- Satunnaisia metsiä
- Keinotekoiset neuroverkot